I am working in Python with a dataset that looks like the following Original Dataset:
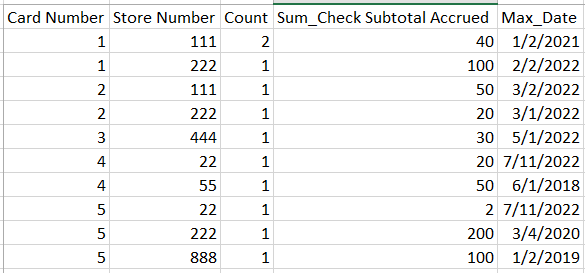
Where Card Number - Unique client identifier
Store Number - Unique store identifier
Count - Count of times a unique store has been visited by a unique client
Sum_Check Subtotal Accrued - Sum a client has spent at a unique store
Max_Date - Last time the unique client visited the unique store
I am trying to turn this into a dataframe that contains the Card Number and Store Number with the following logic applied in this order:
- the most visits
- if the amount of visits is tied at 2 , I want the Store Number with the highest spend
- If the amount of visits is tied at 1 between multiple locations I want the most recently visited location.
So the final output should look as follows:

Currently my code looks like this
#sorting the values so that the most visited locations are at the bottom of the group followed by the highest spend.
#This allows for in the event of a tie for the algo to go to the check subtotal sum field and take the largest value
df = df.sort_values(['Card Number', 'Count', 'Sum_Check Subtotal Accrued', 'Max_Date']).drop_duplicates('Card Number', keep='last')
#dropping fields we no longer need now that our dataset is summarized
df=df.drop(['Count', 'Sum_Check Subtotal Accrued', 'Max_Date], axis = 1)
Which was working until the 3rd logic point was added which requires me to pull the most recent visit if tied at 1. I have tried adding the "Max_Date" field to the above code. However, the "Sum_Check Subtotal Accrued" field doesn't allow this to work for the clients tied at 1.
I am guessing some sort of If statement can solve this but am conceptually stuck on how to approach in this way
Any help is greatly appreciated.
CodePudding user response:
Ok I think I got it:
import pandas as pd
CN = [1, 1, 2, 2, 3, 4, 4, 5, 5, 5]
SN = [111, 222, 111, 222, 444, 22, 55, 22, 222, 888]
Count = [2, 1, 1, 1, 1, 1, 1, 1, 1, 1]
SCSA = [40, 100, 50, 20, 30, 20, 50, 2, 200, 100]
Date = ["1/2/2021", "2/2/2021", "3/2/2021", "3/1/2021", "5/1/2021", "7/11/2022", "6/1/2018", "7/11/2022", "3/4/2020" ,"1/2/2019"]
df = pd.DataFrame({"Card":CN, "Store":SN, "Count":Count, "SCSA":SCSA, "Date":Date})
cards = df.Card.unique()
storeList = []
# Loop through each card uniquely, checking for their max values
for x in cards:
Card = df[df.Card == x]
countMax = Card.Count.max()
dateMax = Card.Date.max()
# If there is only one store with the max visits, add it to the list
if len(Card[Card.Count == countMax]) < 2:
storeList.append(Card.Store[Card.Count == countMax].values[0])
# If the number of visits is >= 2 and there is more than 1 store with this number of visits...
elif (countMax >= 2) and (len(Card[Card.Count == countMax]) > 1):
scsaMax = Card[Card.Count == countMax].SCSA.max() # Find the highest spending of the stores that were visited the most
storeList.append(Card.Store[Card.SCSA == scsaMax].values[0]) # add the store with the most spending of the store that were visited the most
# Otherwise, just add the most recently visited store to the list
else:
storeList.append(Card.Store[Card.Date == dateMax].values[0])
pd.DataFrame({"Card Number":cards, "Store Number":storeList})
Output:
Card Number Store Number
1 111
2 111
3 444
4 22
5 22
I changed some of the visit counts and SCSA values to make sure it was still printing out what I expected it to, seems to be right now.
CodePudding user response:
Try this:
(df.sort_values(['Count', 'Sum_Check Subtotal Accrued', 'Max_Date'],ascending = [0,0,0])
.groupby('Card Number').head(1))