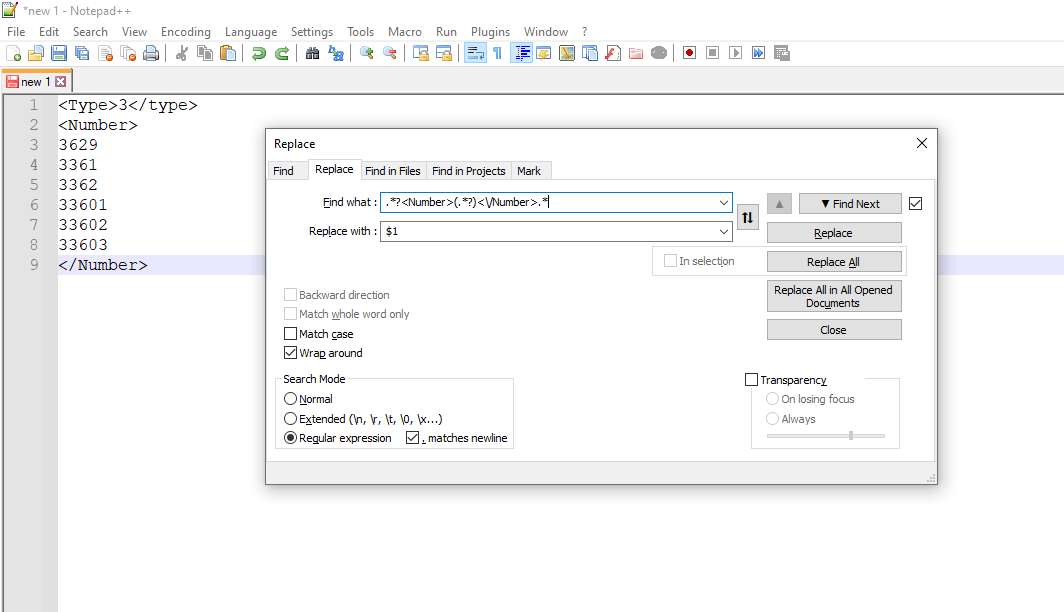
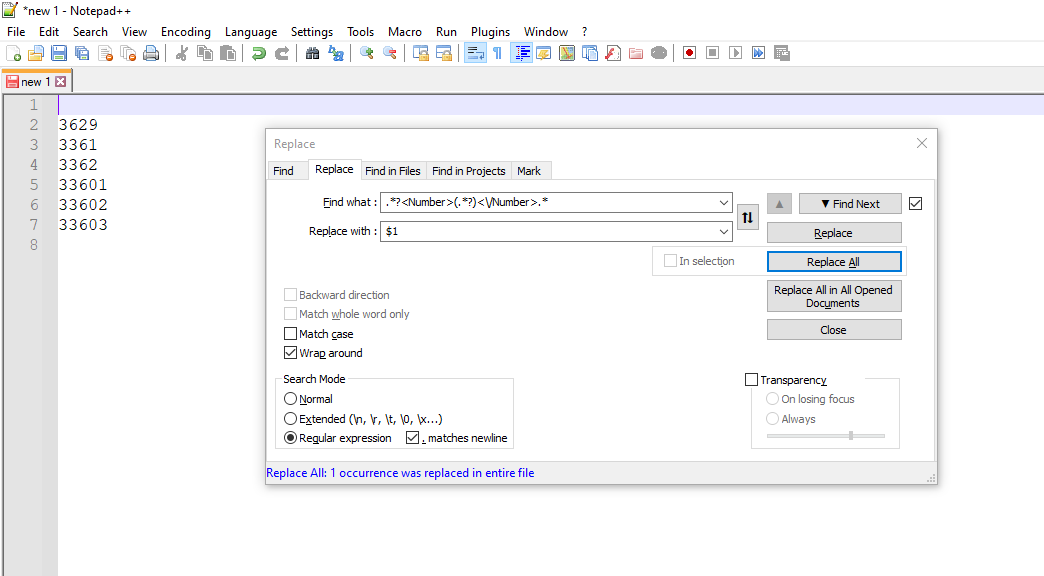
I have a project that demands extracting data from XML files (values inside the <Number>... </Number> tag), however, in my regular expression, I haven't been able to extract lines that had multiple data separated by a newline, see the below example:
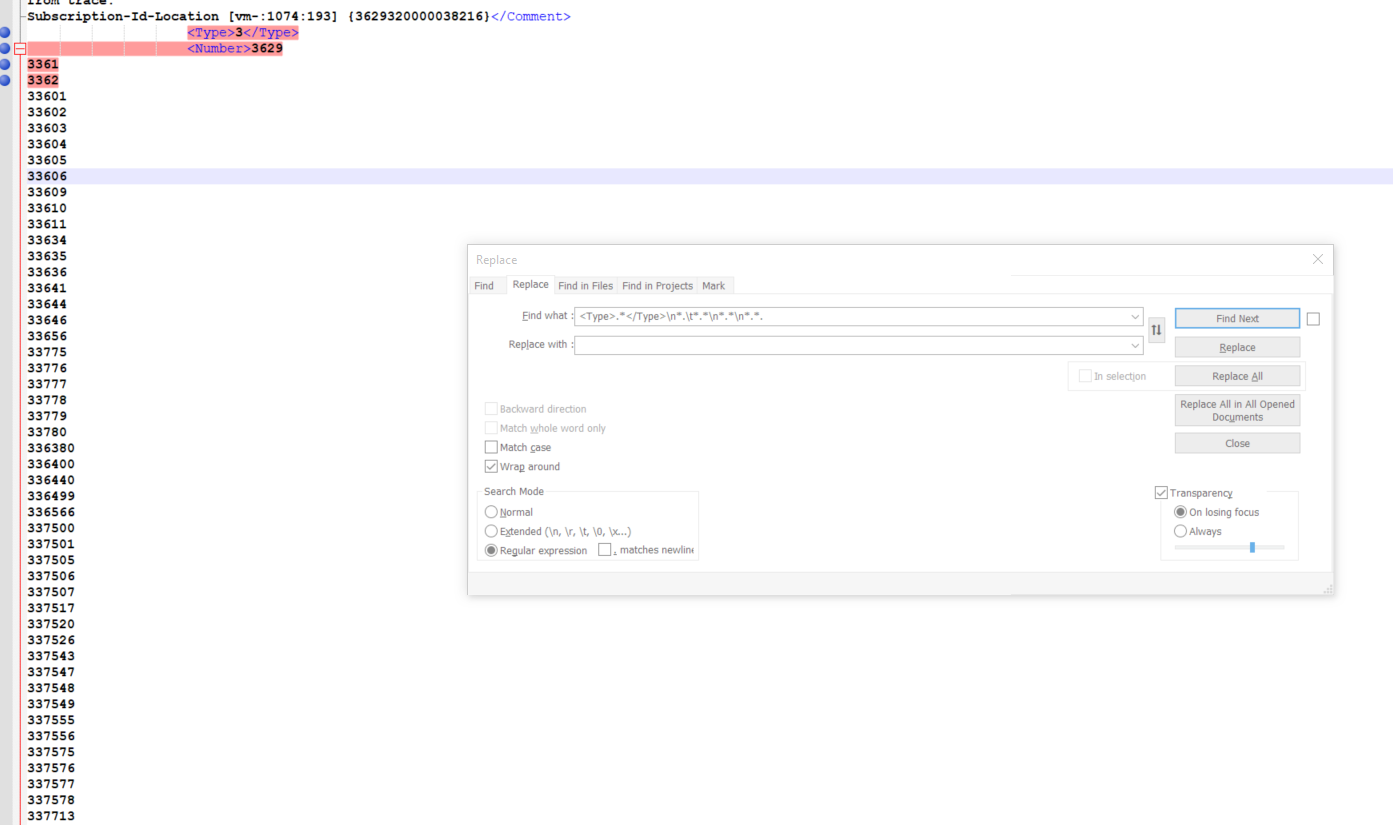
As you can see above, I couldn't replicate the multiple lines detection by my regular expression.
CodePudding user response:
If you are using a script somewhere, your first plan should be to use a XML parser. Almost every language has one and it should be far more accurate compared to using regex. However, if you just want to use regex to search for strings inside npp, then you can use \s to capture multiple new lines:
<Number>(\d \s) <\/Number>