I'd like to create a column that gives a unique CoupleID if ID and PartnerID contain the same values but in any combination, i.e. not in the same columns. The existing questions and answers seem to only refer to cases when the values are duplicated within the same columns, i.e Add ID column by group. Any help would be much appreciated!
This is what I have:
> tibble(df)
# A tibble: 6 × 2
ID PartnerID
1 2
2 1
3 4
4 3
5 6
6 5
This is what I want:
> tibble(df2)
# A tibble: 6 × 3
ID PartnerID CoupleID
1 2 1
2 1 1
3 4 2
4 3 2
5 6 3
6 5 3
Data
df <- data.frame (ID = c("1", "2", "3", "4", "5", "6"),
PartnerID = c("2", "1", "4","3", "6", "5")
)
df2 <- data.frame (ID = c("1", "2", "3", "4", "5", "6"),
PartnerID = c("2", "1", "4","3", "6", "5"),
CoupleID = c("1", "1", "2", "2", "3", "3")
)
CodePudding user response:
Try this
library(dplyr)
df |> rowwise() |> mutate(g = paste0(sort(c_across(ID:PartnerID)) ,
collapse = "")) |> group_by(g) |> mutate(CoupleID = cur_group_id()) |>
ungroup() |> select(-g)
- output
# A tibble: 6 × 3
ID PartnerID CoupleID
<chr> <chr> <int>
1 1 2 1
2 2 1 1
3 3 4 2
4 4 3 2
5 5 6 3
6 6 5 3
CodePudding user response:
There are many methods to do this, here one example. First we sort the rows, then paste it somehow together to get a unique combination, convert it to a factor and retrieve the numerical code of the level ID:
tmp <- apply(df, 1, sort)
df$CoupleID <- as.numeric(factor(paste(tmp[1,], tmp[2,], sep=":")))
df
CodePudding user response:
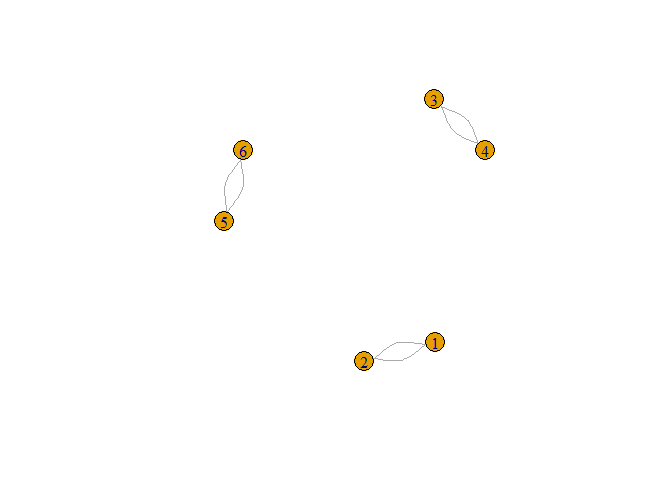
Here is a graph theoretical solution with package igraph.
The new column are the connected components of the undirected graph defined by the data.frame. The plot illustrates this and is not part of the question.
The solution is a 2 code lines one: create the graph and get those components' numbers.
suppressPackageStartupMessages(
library(igraph)
)
df <- data.frame (ID = c("1", "2", "3", "4", "5", "6"),
PartnerID = c("2", "1", "4","3", "6", "5"))
g <- graph_from_data_frame(df, directed = FALSE)
components(g)$membership
#> 1 2 3 4 5 6
#> 1 1 2 2 3 3
plot(g)
df$CoupleID <- components(g)$membership
df
#> ID PartnerID CoupleID
#> 1 1 2 1
#> 2 2 1 1
#> 3 3 4 2
#> 4 4 3 2
#> 5 5 6 3
#> 6 6 5 3
Created on 2022-07-15 by the reprex package (v2.0.1)