I am new to OpenMP and I have to complete this project where I need to resolve a 2D matrix using Jacobi iteration method to resolve a heat conductivity problem using OpenMP.
Essentially It is a plate with four walls at the sides which have fixed temperatures and I need to work out the unknown temperature values in the middle.
The code has been given to us and what I am expected to do is three simple things:
- Time the serial code
- Parallelise the serial code and compare
- Further optimise the parallel code if possible
I have ran the serial code and parallelised the code to make a comparison. Before any optimisation, for some reason the serial code is consistently doing better. I can't help but think I am doing something wrong?
I will try compiler optimisations for both, but I expected parallel code to be faster. I have chosen a large problem size for the matrix including a 100 x 100, 300 x 300 array and every single time almost the serial code is doing better.
Funny thing is, the more threads I add, the slower it gets.
I understand for a small problem size it would be a larger overhead, but I thought this is a large enough problem size?
This is before any significant optimisation, am I doing something obviously wrong that makes it like this?
Here is the code:
Serial code:
#include <stdio.h>
#include <math.h>
#include <stdlib.h>
#include <omp.h>
int main(int argc, char *argv[])
{
int m;
int n;
double tol;// = 0.0001;
int i, j, iter;
m = atoi(argv[1]);
n = atoi(argv[2]);
tol = atof(argv[3]);
/**
* @var t, tnew, diff, diffmax,
* t is the old temprature array,tnew is the new array
*/
double t[m 2][n 2], tnew[m 1][n 1], diff, difmax;
/**
* Timer variables
* @var start, end
*/
double start, end;
printf("%d %d %lf\n",m,n, tol);
start = omp_get_wtime();
// initialise temperature array
for (i=0; i <= m 1; i ) {
for (j=0; j <= n 1; j ) {
t[i][j] = 30.0;
}
}
// fix boundary conditions
for (i=1; i <= m; i ) {
t[i][0] = 33.0;
t[i][n 1] = 42.0;
}
for (j=1; j <= n; j ) {
t[0][j] = 20.0;
t[m 1][j] = 25.0;
}
// main loop
iter = 0;
difmax = 1000000.0;
while (difmax > tol) {
iter ;
// update temperature for next iteration
for (i=1; i <= m; i ) {
for (j=1; j <= n; j ) {
tnew[i][j] = (t[i-1][j] t[i 1][j] t[i][j-1] t[i][j 1]) / 4.0;
}
}
// work out maximum difference between old and new temperatures
difmax = 0.0;
for (i=1; i <= m; i ) {
for (j=1; j <= n; j ) {
diff = fabs(tnew[i][j]-t[i][j]);
if (diff > difmax) {
difmax = diff;
}
// copy new to old temperatures
t[i][j] = tnew[i][j];
}
}
}
end = omp_get_wtime();
// print results,
//Loop tempratures commented out to save performance
printf("iter = %d difmax = %9.11lf\n", iter, difmax);
printf("Time in seconds: %lf \n", end - start);
// for (i=0; i <= m 1; i ) {
// printf("\n");
// for (j=0; j <= n 1; j ) {
// printf("%3.5lf ", t[i][j]);
// }
// }
// printf("\n");
}
Here is the parallel code:
#include <stdio.h>
#include <math.h>
#include <stdlib.h>
#include <omp.h>
int main(int argc, char *argv[])
{
int m;
int n;
double tol;// = 0.0001;
/**
* @brief Integer variables
* @var i external loop (y column array) counter,
* @var j internal loop (x row array counter) counter,
* @var iter number of iterations,
* @var numthreads number of threads
*/
int i, j, iter, numThreads;
m = atoi(argv[1]);
n = atoi(argv[2]);
tol = atof(argv[3]);
numThreads = atoi(argv[4]);
/**
* @brief Double variables
* @var t, tnew -> The variable that holds the temprature, the t is the old value and the tnew is the new value,
* @var diff Measures the difference,
* @var diffmax
* t is the temprature array, I guess it holds the matrix?
*
*/
double t[m 2][n 2], tnew[m 1][n 1], diff, diffmax, privDiffmax;
/**
* Timer variables
* @var start, end
*/
double start, end;
/**
* @brief Print the problem size & the tolerance
* This print statement can be there as it is not part of the parallel region
* We also print the number of threads when printing the problem size & tolerance
*/
//printf("%d %d %lf %d\n",m,n, tol, numThreads);
omp_set_num_threads(numThreads);
/**
* @brief Initialise the timer
*
*/
start = omp_get_wtime();
/**
* @brief Creating the parallel region:
* Here both loop counters are private:
*/
#pragma omp parallel private(i, j)
{
/**
* @brief initialise temperature array
* This can be in a parallel region by itself
*/
#pragma omp for collapse(2) schedule(static)
for (i=0; i <= m 1; i ) {
for (j=0; j <= n 1; j ) {
t[i][j] = 30.0;
}
}
// fix boundary conditions
#pragma omp for schedule(static)
for (i=1; i <= m; i ) {
t[i][0] = 33.0;
t[i][n 1] = 42.0;
}
#pragma omp for schedule(static)
for (j=1; j <= n; j ) {
t[0][j] = 20.0;
t[m 1][j] = 25.0;
}
}
// main loop
iter = 0;
diffmax = 1000000.0;
while (diffmax > tol) {
iter = iter 1;
/**
* @brief update temperature for next iteration
* Here we have created a parallel for directive, this is the second parallel region
*/
#pragma omp parallel for private(i, j) collapse(2) schedule(static)
for (i=1; i <= m; i ) {
for (j=1; j <= n; j ) {
tnew[i][j] = (t[i-1][j] t[i 1][j] t[i][j-1] t[i][j 1]) / 4.0;
}
}
// work out maximum difference between old and new temperatures
diffmax = 0.0;
/**
* @brief Third parallel region that compares the difference
*/
#pragma omp parallel private(i, j, privDiffmax, diff)
{
privDiffmax = 0.0;
#pragma omp for collapse(2) schedule(static)
for (i=1; i <= m; i ) {
for (j=1; j <= n; j ) {
diff = fabs(tnew[i][j]-t[i][j]);
if (diff > privDiffmax) {
privDiffmax = diff;
}
// copy new to old temperatures
t[i][j] = tnew[i][j];
}
}
#pragma omp critical
if (privDiffmax > diffmax)
{
diffmax = privDiffmax;
}
}
}
//Add timer for the end
end = omp_get_wtime();
// print results,
//Loop tempratures commented out to save performance
printf("iter = %d diffmax = %9.11lf\n", iter, diffmax);
printf("Time in seconds: %lf \n", end - start);
// for (i=0; i <= m 1; i ) {
// printf("\n");
// for (j=0; j <= n 1; j ) {
// printf("%3.5lf ", t[i][j]);
// }
// }
// printf("\n");
}
Here are some of the benchmarks for serial code:

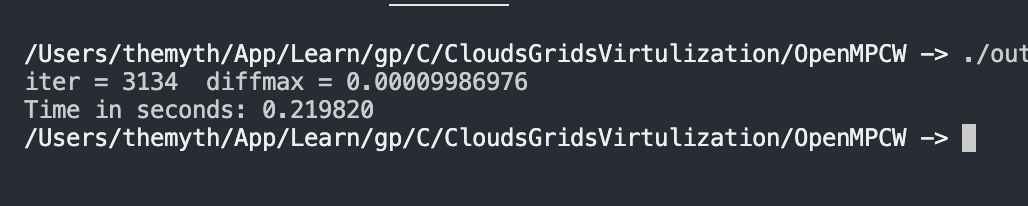

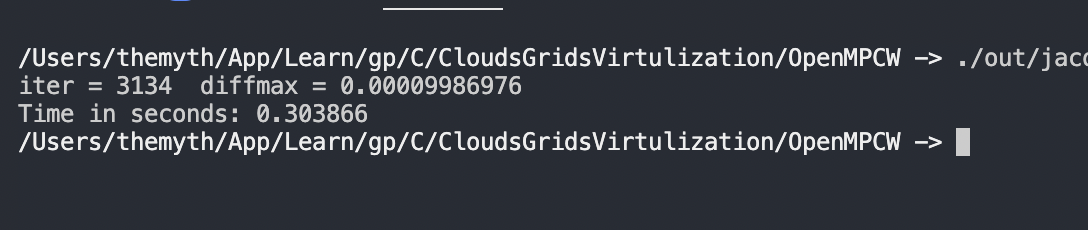
I have ran the code and tested it, I have commented out the print statements as I dont need to see that except for to test. The code runs fine but somehow it is slower than the serial code.
I have an 8 core Apple Mac M1
I am new to OpenMP and can't help but think I am missing something. Any advice would be appreciated
CodePudding user response:
The problem comes from the overhead of collapse(2) on Clang. I can reproduce the problem on Clang 13.0.1 in both -O0 and -O2 on a x86-64 i5-9600KF processor, but not on GCC 11.2.0. Clang generates an inefficient code when collapse(2) is used: it uses an expensive div/idiv instruction in the hot loop to be able to compute the i and j indices. Indeed, here is the assembly code of the hot loop of the sequential version (in -O1 to make the code more compact):
.LBB0_27: # Parent Loop BB0_15 Depth=1
movsd xmm3, qword ptr [rbx 8*rsi] # xmm3 = mem[0],zero
movapd xmm5, xmm3
subsd xmm5, qword ptr [rdi 8*rsi]
andpd xmm5, xmm0
maxsd xmm5, xmm2
movsd qword ptr [rdi 8*rsi], xmm3
add rsi, 1
movapd xmm2, xmm5
cmp r12, rsi
jne .LBB0_27
Here is the parallel counterpart (still in -O1):
.LBB3_4:
mov rax, rcx
cqo
idiv r12 # <-------------------
shl rax, 32
add rax, rdi
sar rax, 32
mov rbp, rax
imul rbp, r13 # <-------------------
shl rdx, 32
add rdx, rdi
sar rdx, 32
add rbp, rdx
movsd xmm2, qword ptr [r9 8*rbp] # xmm2 = mem[0],zero
imul rax, r8 # <-------------------
add rax, rdx
movapd xmm3, xmm2
subsd xmm3, qword ptr [rsi 8*rax]
andpd xmm3, xmm0
maxsd xmm3, xmm1
movsd qword ptr [rsi 8*rax], xmm2
add rcx, 1
movapd xmm1, xmm3
cmp rbx, rcx
jne .LBB3_4
There are much more instructions to execute because the loop spent most of the time computing indices. You can fix this by not using the collapse clause. Theoretically, it should be better to provide more parallelism to compilers and runtime to let them make the best decisions, but in practice they are not optimal and they often need to be assisted/guided. Note that GCC uses a more efficient approach that consists in computing the division only once per block, so compilers can do this optimization.
Results
With `collapse(2)`:
- Sequential: 0.221358 seconds
- Parallel: 0.274861 seconds
Without:
- Sequential: 0.222201 seconds
- Parallel: 0.055710 seconds
Additional notes on performance
For better performance, consider using -O2 or even -O3. Also consider using -march=native. -ffast-math can also help if you do not use special floating-point (FP) values like NaN and you do not care about FP associativity. Not copying the array every time and using a double-buffering method also helps a lot (memory-bound codes do not scale well). Then consider reading a research paper for better performance (trapezoidal tiling can be used to boost the performance even more but this is quite complex to do). Also note that not using collapse(2) reduce the amount of parallelism which might be a problem on a processor with a lot of cores but in practice having a lot of cores operating on a small array tends to be slow anyway (because of false-sharing and communications).
Special note for M1 processors
M1 processors are based on a Big/Little architecture. Such an architecture is good to make sequential codes faster thanks to the few "big" cores that run fast (but also consume a lot of space and energy). However, running efficiently parallel core is harder because the "little" cores (which are energy efficient and small) are much slower than the big ones introducing load-imbalance issue if all kinds of cores are running simultaneously (IDK if this is the case on M1 by default). One solution is to control the execution so to only use the same kind of core. Another solution is to use a dynamic scheduling so to balance the work automatically at runtime (eg. using the clause schedule(guided) or even schedule(dynamic)). The second solution tends to add significant overhead and is known to cause other tricky issues on (NUMA-based) computing servers (or even recent AMD PC processors). It is also important to note that the scaling will not be linear with the number of threads because of the performance difference between the big and little cores. Such architecture is currently poorly efficiently supported by a lot of applications because of the above issues.