I have the following dataframe:
Name
----------
0 Blue
1 Blue
2 Blue
3 Red
4 Red
5 Blue
6 Blue
7 Red
8 Red
9 Blue
I want to count the number of times "Name" = "Blue" and "Name" = "Red" and send that to a dictionary, which for this df would look like:
print('Dictionary:')
dictionary = df['Name'].value_counts().to_dict()
and output the following:
Dictionary:
{'Blue': 5, 'Red': 4}
Ok, straightforward there. So for context, with my data, I KNOW that the only possibilities for "Names" is either "Blue" or "Red". And so I want to account for other dataframes with the same "Name" column, but different frequencies of "Blue" and "Red". Specifically, since the above code works fine, I want to account for instances where there are either NO counts of "Blue" or NO counts of "Red".
And so, if the above df looked like:
Name
----------
0 Blue
1 Blue
2 Blue
3 Blue
4 Blue
5 Blue
6 Blue
7 Blue
8 Blue
9 Blue
I would want the output dictionary via:
print('Dictionary:')
dictionary = df['Name'].value_counts().to_dict()
to produce:
Dictionary:
{'Blue': 9, 'Red': 0}
However, as the code stands, the following is actually produced:
Dictionary:
{'Blue': 9}
I need that 0 value in there for use in another operation. I would like the same to be true if all of the "Name" names were "Red", and so producing:
Dictionary:
{'Blue': 0, 'Red': 9}
and not:
Dictionary:
{'Red': 9}
The problem is that I am running into a situation where I face the issue of counting the frequency of a value (a string occurrence here) that just does not exist. How can I fix my python code so that if the "Name" blue or red never occur, the dictionary will still include that "Name" in the dictionary, but just mark its value as 0?
CodePudding user response:
I think if you change the type of the column in the dataframe to categorical and specify the categories you expect explicitly, you will get the answer you're looking for:
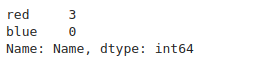
df = pd.DataFrame({'Name': ['red', 'red', 'red']})
df['Name'] = pd.Categorical(df['Name'], categories=['red', 'blue'])
df['Name'].value_counts()
Output:
CodePudding user response:
In Python 3.9 you can use PEP 584's Union Operator:
base = {'Blue': 0, 'Red': 0}
counts = df['Name'].value_counts().to_dict()
dictionary = base | counts
# or just
dictionary = {'Blue': 0, 'Red': 0} | df['Name'].value_counts().to_dict()
Before that you could use unpacking and (re)packing:
base = {'Blue': 0, 'Red': 0}
counts = df['Name'].value_counts().to_dict()
dictionary = {**base, **counts}
You could also use .update,
dictionary = {'Blue': 0, 'Red': 0}
dictionary.update(df['Name'].value_counts().to_dict())
Or iterate over values and use .setdefault:
dictionary = df['Name'].value_counts().to_dict()
for k in ['Blue', 'Red']:
dictionary.setdefault(k, 0)
I'm sure there are other ways as well.