I'm afraid I'll despair soon. I am importing an Excel file, and this always worked in this way for me. But nowI am getting an empty dataframe, and I don't know why?
My demo code looks like this:
import pandas as pd
data = pd.read_excel ('import.xlsx', sheet_name=["Sheet 1", "Sheet 2"], dtype=str)
print (data)
df = pd.DataFrame(data, columns=["Header A", "Header B"] , dtype=str)
print (df)
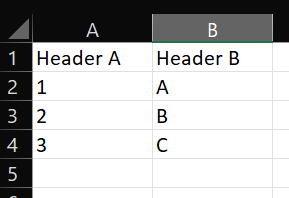
My excel file consists of two sheets, and each sheet looks like this:
| Header A | Header B |
|:--------:|:--------:|
| 1 | A |
| 2 | B |
| 3 | C |
And this it the ouput:
{'Sheet 1': Header A Header B
0 1 A
1 2 B
2 3 C, 'Sheet 2': Header A Header B
0 1 A
1 2 B
2 3 C}
Empty DataFrame
Columns: [A, B]
Index: []
Import works well, because when I print the data dict the data is there. But the DataFrame is empty. I looked for white spaces in the column names, etc. Even if I import only one sheet, the dataframe remains empty. But why?
CodePudding user response:
I can't test it but it seems it gives dictionary with many dataframes and if you want to work with single sheet (single dataframe) then you should get it directly
df = data["Sheet1"]
CodePudding user response:
You don't need to pass the data to dataframe. The dictionary contains the dataframe as the value of key sheet 1 and sheet 2
To solve this problem: you can apply slicing from the dict using the key below
df = data['Sheet 1']
and then append the second sheet to dataframe as second column by slicing like
df['Header B'] = data['Sheet 2']
CodePudding user response:
What's the output you want? (since both sheets are the same)
try:
df = pd.concat(pd.read_excel("import.xlsx", sheet_name=None, dtype=str), ignore_index=False)
if you want this:
Header A Header B
Sheet1 0 1 A
1 2 B
2 3 C
Sheet2 0 1 A
1 2 B
2 3 C
or:
df = pd.concat(pd.read_excel("import.xlsx", sheet_name=None, dtype=str), ignore_index=True)
if you want this:
Header A Header B
0 1 A
1 2 B
2 3 C
3 1 A
4 2 B
5 3 C
I used sheet_name=None since you said your excel file only consists of these two sheets.