I have been trying to create a new column in a dataset, however, it has been not working.
df2 = pd.DataFrame([[1, 'born'], [2, '8 a 14'], [3,'born'], [4,'14 a 21'], [8,'0 a 7'], [10,'die'], [7,'lost']], columns = ["Pen",'Result']) def myFunc(record):
for i in df['Result']:
if (df['Result']=='born').any():
return 'eclosion'
elif (df['Result']=='1 a 7').any():
return 'early'
elif (df['Result']=='8 a 14').any():
return 'mediun'
elif (df['Result']=='15 a 21').any():
return 'late'
df['Final'] = df.apply(myFunc, axis=1)
df
that is the result:
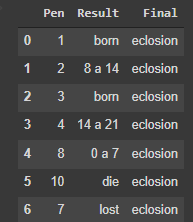
CodePudding user response:
First thing, if your goal is simple to map, use:
d = {'born': 'eclosion', '1 a 7': 'early', '8 a 14':'mediun', '15 a 21': 'late'}
df2['Final'] = df2['Result'].map(d)
# or to keep original values on no match:
df2['Final2'] = df2['Result'].map(d).fillna(df2['Result'])
output:
Pen Result Final Final2
0 1 born eclosion eclosion
1 2 8 a 14 mediun mediun
2 3 born eclosion eclosion
3 4 14 a 21 NaN 14 a 21
4 8 0 a 7 NaN 0 a 7
5 10 die NaN die
6 7 lost NaN lost
If you want the shown output, find the first value in the desired order and map it:
d = {'born': 'eclosion', '1 a 7': 'early', '8 a 14':'mediun', '15 a 21': 'late'}
idx = (df2.drop_duplicates('Result').set_index('Result')
.reindex(list(d)).first_valid_index()
)
df2['Final'] = d.get(idx, None)
output:
Pen Result Final
0 1 born eclosion
1 2 8 a 14 eclosion
2 3 born eclosion
3 4 14 a 21 eclosion
4 8 0 a 7 eclosion
5 10 die eclosion
6 7 lost eclosion
CodePudding user response:
Problem in your code is that your Result column contains born so (df['Result']=='born').any() will return True and never go into elif part.
You can use np.select instead
df['Final'] = np.select(
[df['Result']=='born', df['Result']=='1 a 7',
df['Result']=='8 a 14', df['Result']=='15 a 21'],
['eclosion', 'early', 'mediun', 'late'],
df['Result']
)
CodePudding user response:
The entire code works perfect for me, once you change df2 to be df in the first line to match the rest of the code.