my goal is to find if the following df has a 'circulation'
given:
df = pd.DataFrame({'From':['USA','UK','France','Italy','Russia','china','Japan','Australia','Russia','Italy'],
'to':['UK','France','Italy','Russia','china','Australia','New Zealand','Japan','USA','France']})
df

and if I graph it, it would look like this (eventually, note that the order on the df is different):
USA-->UK-->France-->Italy-->Russia-->China-->Australia-->Japan-->Australia
| |
| |
France USA
The point is this: You cannot go backward, so Italy cannot go to France and Russia cannot go to USA.
Note: From can have multiple Tos
How can I find it in pandas so the end result would look like this:
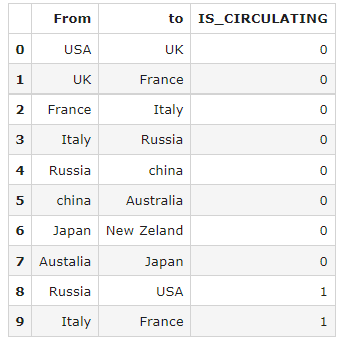
I can solve it without pandas (I get df.to_dict('records') and then iterate to find the circulation and then go back to pandas) but I wish to stay on pandas.
CodePudding user response:
The logic is not fully clear, however you can approach your problem with a graph.
Your graph is the following:
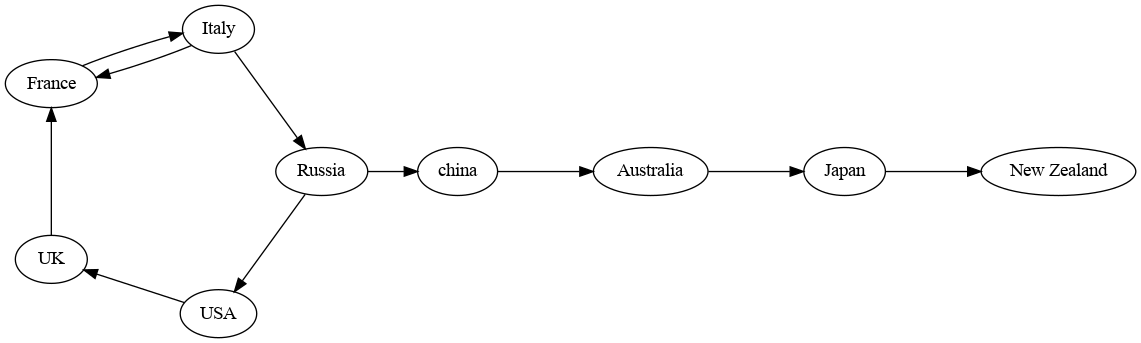
Let us consider circulating nodes, those that have more than one destination.
You can obtain this with networkx:
import networkx as nx
G = nx.from_pandas_edgelist(df, source='From', target='to', create_using=nx.DiGraph)
circulating = {n for n in G if len(list(G.successors(n)))>1}
df['IS_CIRCULATING'] = df['From'].isin(circulating).astype(int)
output:
From to IS_CIRCULATING
0 USA UK 0
1 UK France 0
2 France Italy 0
3 Italy Russia 1
4 Russia china 1
5 china Australia 0
6 Japan New Zealand 0
7 Australia Japan 0
8 Russia USA 1
9 Italy France 1
With pure pandas:
df['IS_CIRCULATING'] = df.groupby('From')['to'].transform('nunique').gt(1).astype(int)