currently i have two cvs files, one is the temporary file (df1) which has 10 columns, the other is the Master file (df2) and has only 2 columns. I would like to iterate over rows and compare values from a column that is in both files (UserName) and if the value of UserName is already present in the Master File, add the value of the other column that appears in both files (Score) to the value of Score in Master File (df2) for that specific user. If on the other hand, the value of UserName from the temporary file is not present in the Master File, just append row to the Master Table as new row.
example Master file (df2):
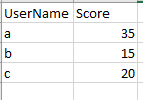
example temp file (df1):
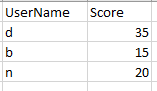
new master file i would like to obtain after comparison:
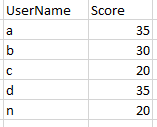
i have the following code but currently it appends all rows every time a comparison is made between the 2 files, could use some help to determine if it's even a good approach for the described problem:
import os
import win32com.client
import pandas as pd
import numpy as np
path = os.path.expanduser("Attachments")
MasterFile=os.path.expanduser("MasterFile.csv")
fields = ['UserName', 'Score']
df1 = pd.read_csv(zipfilepath, skipinitialspace=True, usecols=fields)
df2 = pd.read_csv(MasterFile, skipinitialspace=True, usecols=fields)
comparison_values = df1['UserName'].values == df2['UserName'].values
print(comparison_values)
rows = np.where(comparison_values == False)
for item in comparison_values:
if item==True:
df2['Score']=df2['Score'] df1['Score']
else:
df2 = df2.append(df1[{'UserName', 'Score'}], ignore_index=True)
df2.to_csv(MasterFile, mode='a', index=False, header=False)
EDIT**
what about a mix of integers and strings in the 2 files? Example
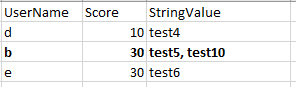
Example Master File (df2):
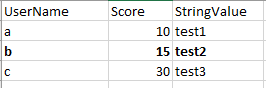
Example temp file (df1):
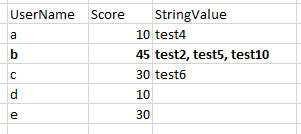
new master file i would like to obtain after comparison:
CodePudding user response:
IIUC, you can use
df = pd.concat([df1, df2]).groupby('UserName', as_index=False).sum()