I have a dataframe as follows,
df_names = pd.DataFrame({'last_name':['Williams','Henry','XYX','Smith','David','Freeman','Walter','Test_A'],
'first_name':['Henry','Williams','ABC','David','Smith','Walter','Freeman','Test_B']})
A new column full name adding last and first names as below -
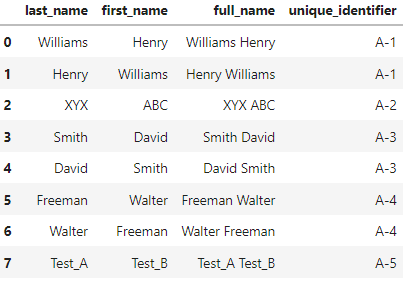
Here i would like to check how similar the full names are ? Williams Henry and Henry Williams to be considered as same and give it a unique identifier some random code.
similarly Smith David and David Smith should also be consider as one unique identifier.
Final expected output as below.
CodePudding user response:
Use:
res = (df_names.assign(group=df_names[["last_name", "first_name"]].apply(frozenset, axis=1))
.groupby("group")
.ngroup() 1)
df_names["unique_identifier"] = "A-" res.astype("string")
print(df_names)
Output
last_name first_name unique_identifier
0 Williams Henry A-1
1 Henry Williams A-1
2 XYX ABC A-2
3 Smith David A-3
4 David Smith A-3
5 Freeman Walter A-4
6 Walter Freeman A-4
7 Test_A Test_B A-5
The idea is to use frozenset to map each row to an object where the order of the elements is irrelevant. It has to be a frozenset so is hashable, this is a requirement of pandas.
CodePudding user response:
Try this:
a = df_names.groupby(lambda idx: tuple(sorted(df_names.iloc[idx])))
Output:
a.apply(print)
last_name first_name
2 XYX ABC
last_name first_name
5 Freeman Walter
6 Walter Freeman
last_name first_name
0 Williams Henry
1 Henry Williams
last_name first_name
3 Smith David
4 David Smith
last_name first_name
7 Test_A Test_B