I have a dataframe as:
{'last_name': {0: 'Acosta-Arriola',
1: 'Afragola',
2: 'Bertolini',
3: 'Coyle',
4: 'Davis',
10: 'Duntz',
11: 'Eastman',
12: 'Fitzgerald',
13: 'Fitzgerald',
14: 'Freeman',
15: 'Freeman',
16: 'Gambardella',
17: 'Kelleher',
18: 'King',
19: 'Looney',
20: 'Mccann',
21: 'Murray',
22: 'Palmeri',
23: 'Powers',
24: 'Vitelli',
25: 'Wyzykowski'},
'first_name_or_initial': {0: 'Jose',
1: 'Sarah',
2: 'Peter',
3: 'James',
4: 'Albert',
10: 'Shawn',
11: 'Bryan',
12: 'Richard',
13: 'Richard',
14: 'Matthew',
15: 'Matthew',
16: 'Vincent',
17: 'Robert',
18: 'Thomas',
19: 'Ray',
20: 'Joseph',
21: 'Joshua',
22: 'Randy',
23: 'Dennis',
24: 'Robert',
25: 'John'},'middle_name_or_initial': {0: 'Lusi;Luis',
1: 'R.;B.',
2: 'M.;Mario',
3: 'M.;Michael',
4: 'Chadbourne;C.',
10: 'R.;Richard',
11: 'J.;James',
12: 'M.;J.;Micha',
13: 'M.;Michael',
14: 'Christopher;Robert',
15: 'Christopher;C.',
16: 'A.;Anthony',
17: 'S.;Steven',
18: 'E.;Emory',
19: 'S.;Scott',
20: 'M.;Michael',
21: 'M.;P.',
22: 'T.;Thomas',
23: 'E.;Edward',
24: 'J.;D.',
25: 'J.;James'},
'Suffix': {0: '',
1: '',
2: '',
3: '',
4: 'Jr.',
10: '',
11: '',
12: '',
13: '',
14: '',
15: '',
16: '',
17: '',
18: 'Jr.',
19: 'Jr.',
20: '',
21: '',
22: '',
23: 'Jr.',
24: '',
25: ''},
'address_1': {0: '',
1: '51 Indigo Trail',
2: '90 Cherry Street;1295 Great Hill Road;90 Cherry Street',
3: '51 Canary Court;51 Canary Court;687 Main Street',
4: '39 Hemenway Street',
10: '118 Brookside Avenue;9886 171 Street Place',
11: '616 East Main Street;989 Boston Post Road;38 Mallard Court;1421 Naugatuck Avenue',
12: '',
13: '18 Fox Ridge Lane;18 Fox Ridge;18 Fox Ridge Road',
14: '',
15: '',
16: '45 Jakobs Landing',
17: '171 Williams Road;181 Knob Hill Road',
18: '31 Millwood Drive;31 Millwood Drive;41 Waverly Park Road;31 Millwood Drive;25 Crouch Road',
19: '',
20: '17 Pheasant Run;25 Mcdermott Road;PO Box 510;17 Pheasant Run',
21: '42 Seymour Street;42 Seymour Stt',
22: '205 Mccall Road',
23: '204 Milton Avenue;187 Milton Avenue',
24: '16 Montgomery Drive',
25: '457 Hill Street;139 County Line Road'}}
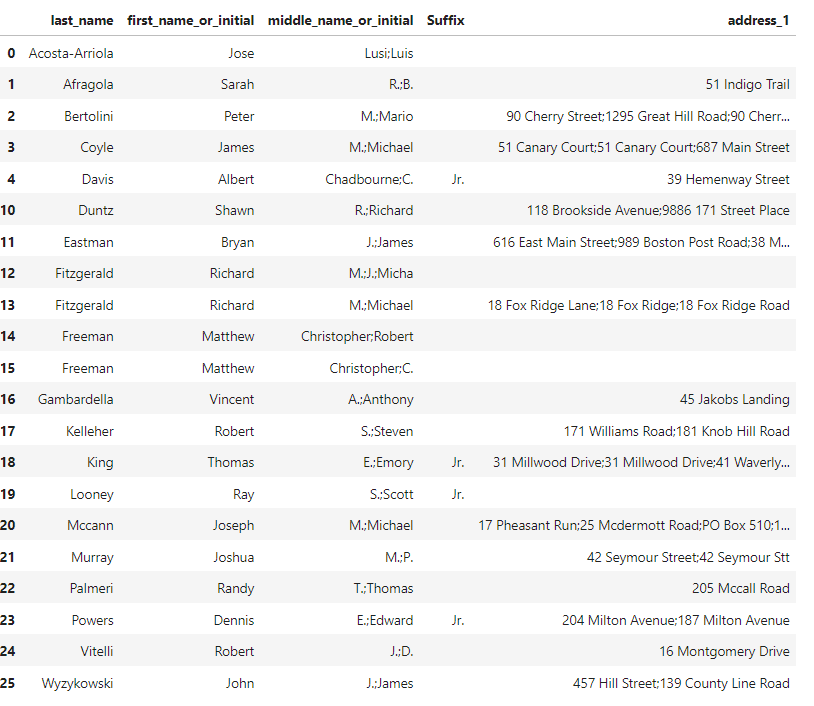
Here i would like to split a column middle_name using delimeter semicolon ';'.
after splitting i would like to have a additional rows as many spitted words as existed.
for example:
Duntz Shawn R.;Richard 118 Brookside Avenue;9886 171 Street Place
should be
1. Duntz - Shawn - R. - 118 Brookside Avenue;9886 171 Street Place
2. Duntz - Shawn - Richard - 118 Brookside Avenue;9886 171 Street Place
CodePudding user response:
# split the middle name
df.middle_name_or_initial = df.middle_name_or_initial.str.split(';')
# explode the dataframe
df_new = df.explode('middle_name_or_initial')
here is the documentation of df.explode()
doc