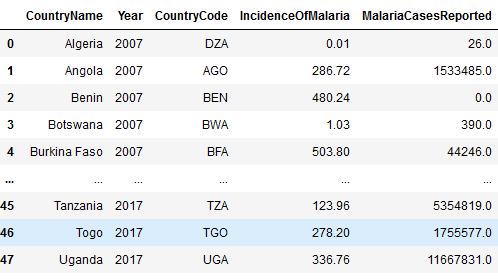
I'm trying to
- step 1. Get the min incidence of malaria for each country
- step2 -If a country has a nan value in the 'IncidenceOfMalaria' column, fill nan values with the minimum value of that column FOR THAT VERY COUNTRY AND NOT THE MIN VALUE OF THE ENTIRE COLUMN.
My attempt
malaria_data = pd.read_csv('DatasetAfricaMalaria.csv')
malaria_data["IncidenceOfMalaria"].groupby(malaria_data['CountryName']).min().sort_values()
I get a series like so
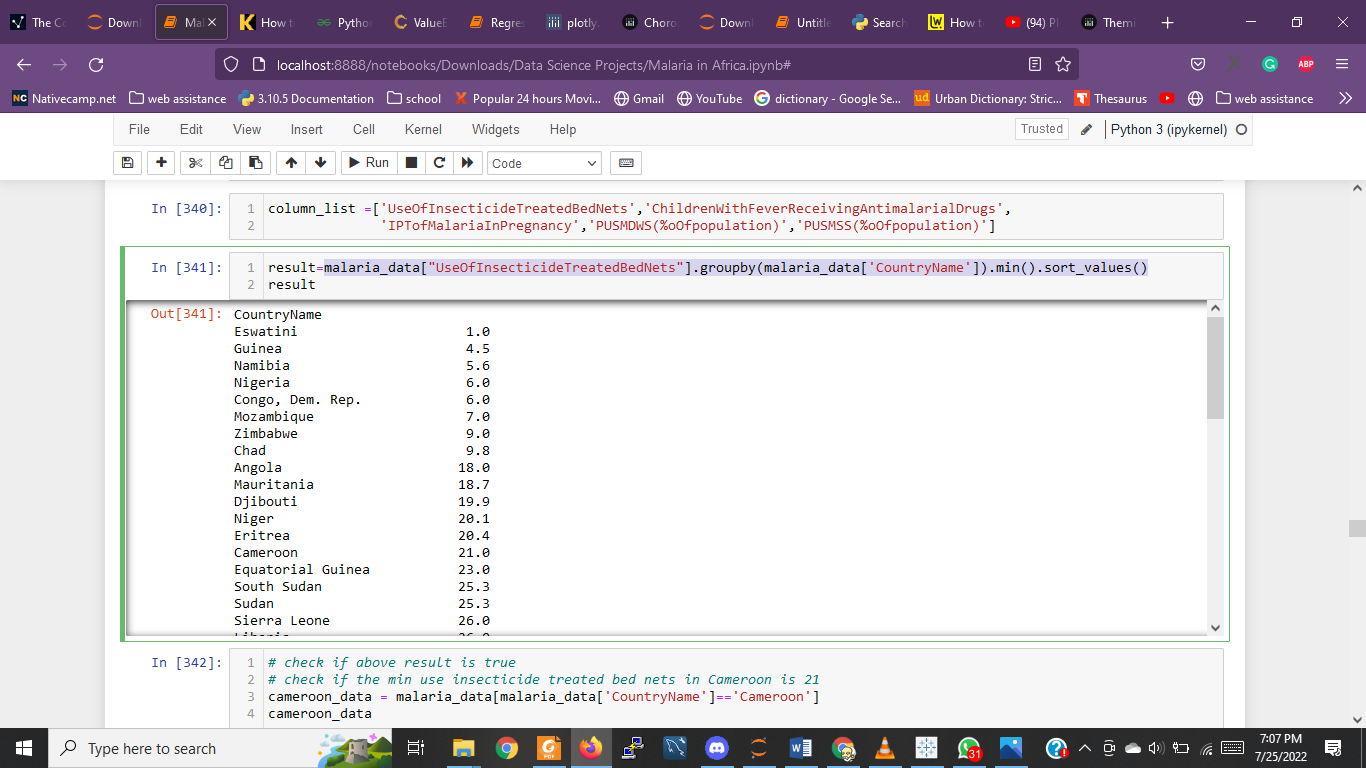
Stuck at this level. How can I proceed or what would you rather have me do differently?
CodePudding user response:
A better approach would be something like this
malaria_data.groupby('CountryName')['IncidenceOfMalaria'].apply(lambda gp : gp.fillna(gp.min())
Will probably give you what you want, i didnt test it out because there is no sample data but please tell me if an error occurs.