I have a following table structure in the MS SQL server
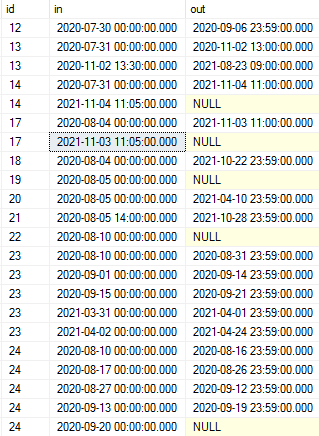
Now, I want to get [in] dates for each [id] according to these rules:
- If there is [out] at 23:59 and [in] at 00:00 on the next day ignore these
- If there is [out] and [in] on the same day ignore these
e.g. I should be getting following results:
| id | in | out |
|---|---|---|
| 12 | 2020-07-30 | 2020-09-06 |
| 13 | 2020-07-31 | 2021-08-23 |
| 14 | 2020-07-31 | NULL |
...
| id | in | out |
|---|---|---|
| 23 | 2020-08-10 | 2020-09-21 |
| 23 | 2021-03-31 | 2021-04-24 |
| 24 | 2020-08-10 | NULL |
...
I do not care about the [out]s, so they are not mandatory. Is there a simple way to achieve this?
I came with something like this:
select *from #temp1
EXCEPT
select t1.* from #temp1 t1
INNER join #temp1 t2
ON t1.id =t2.id
and (t1.[in] = DATEADD(minute,1,t2.[out]) or DAY(t1.[in]) = DAY(t2.[out]))
But I am losing some data, e.g. the second [in] for Id 23 from the example.
CodePudding user response:
I am confident there is a better solution than this. I wrestled with a 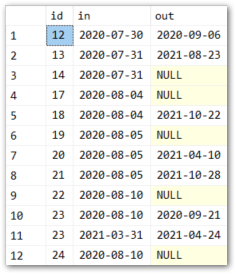
Here is the dbfiddle.
Certainly my approach could be made more concise (i.e. less sub-queries), but I left them in there so they can be run from the inside out and you can see the progression of the logic. I think I could have avoided using the ROW_NUMBER() function if I could have gotten the LAST_VALUE() function to work. Either I do not know how to use it or it is broken, likely the former.
Finally, I would recommend to not use keywords such as "in" for column names. I just makes things simpler.
Noel
CodePudding user response:
Leveraging a recursive CTE (Common Table Expression) yields a cleaner approach imho. I'm not sure how it compares to Isaac's approach performance wise so you have to test that yourself.
Setup:
DROP TABLE IF EXISTS MyTable;
CREATE TABLE MyTable(
id INTEGER NOT NULL
,[in] VARCHAR(19) NOT NULL
,[out] VARCHAR(19)
);
INSERT INTO MyTable([id],[in],[out]) VALUES (12,'2020-07-30 00:00:00','2020-09-06 23:59:00');
INSERT INTO MyTable([id],[in],[out]) VALUES (13,'2020-07-31 00:00:00','2020-11-02 13:00:00');
INSERT INTO MyTable([id],[in],[out]) VALUES (13,'2020-11-02 13:30:00','2021-08-23 09:00:00');
INSERT INTO MyTable([id],[in],[out]) VALUES (14,'2020-07-31 00:00:00','2021-11-04 11:00:00');
INSERT INTO MyTable([id],[in],[out]) VALUES (14,'2021-11-04 11:05:00',NULL);
INSERT INTO MyTable([id],[in],[out]) VALUES (17,'2020-08-04 00:00:00','2021-11-03 11:00:00');
INSERT INTO MyTable([id],[in],[out]) VALUES (17,'2021-11-03 11:05:00',NULL);
INSERT INTO MyTable([id],[in],[out]) VALUES (18,'2020-08-04 00:00:00','2021-10-22 23:59:00');
INSERT INTO MyTable([id],[in],[out]) VALUES (19,'2020-08-05 00:00:00',NULL);
INSERT INTO MyTable([id],[in],[out]) VALUES (20,'2020-08-05 00:00:00','2021-04-10 23:59:00');
INSERT INTO MyTable([id],[in],[out]) VALUES (21,'2020-08-05 14:00:00','2021-10-28 23:59:00');
INSERT INTO MyTable([id],[in],[out]) VALUES (22,'2020-08-10 00:00:00',NULL);
INSERT INTO MyTable([id],[in],[out]) VALUES (23,'2020-08-10 00:00:00','2020-08-31 23:59:00');
INSERT INTO MyTable([id],[in],[out]) VALUES (23,'2020-09-01 00:00:00','2020-09-14 23:59:00');
INSERT INTO MyTable([id],[in],[out]) VALUES (23,'2020-09-15 00:00:00','2020-09-21 23:59:00');
INSERT INTO MyTable([id],[in],[out]) VALUES (23,'2021-03-31 00:00:00','2021-04-01 23:59:00');
INSERT INTO MyTable([id],[in],[out]) VALUES (23,'2021-04-02 00:00:00','2021-04-24 23:59:00');
INSERT INTO MyTable([id],[in],[out]) VALUES (24,'2020-08-10 00:00:00','2020-08-16 23:59:00');
INSERT INTO MyTable([id],[in],[out]) VALUES (24,'2020-08-17 00:00:00','2020-08-26 23:59:00');
INSERT INTO MyTable([id],[in],[out]) VALUES (24,'2020-08-27 00:00:00','2020-09-12 23:59:00');
INSERT INTO MyTable([id],[in],[out]) VALUES (24,'2020-09-13 00:00:00','2020-09-19 23:59:00');
INSERT INTO MyTable([id],[in],[out]) VALUES (24,'2020-09-20 00:00:00',NULL);
Solution:
WITH base AS
(
SELECT id, [in], out, ROW_NUMBER() OVER (ORDER BY id, [in]) AS seq
FROM (SELECT *,
LAG(out) OVER (PARTITION BY id ORDER BY [in]) AS prev_out
FROM MyTable) T
WHERE prev_out IS NULL
OR (DATEADD(MINUTE, -1, [in]) != prev_out AND CAST([in] AS DATE) != CAST(prev_out AS DATE))
),
walker AS (
SELECT id, [in], out, seq FROM base
UNION ALL
SELECT walker.id, MyTable.[in], MyTable.out, walker.seq
FROM MyTable
INNER JOIN walker
ON MyTable.id = walker.id
AND (DATEADD(MINUTE, 1, MyTable.[in]) = walker.out
OR CAST(MyTable.[in] AS DATE) = CAST(walker.out AS DATE))
)
SELECT id,
MIN(CAST([in] AS DATE)) AS [in],
MAX(CAST(out AS DATE)) AS out
FROM walker
GROUP BY id, seq
ORDER BY id, seq, [in];
Output: | id | in | out | | :--- | :--- | :--- | | 12 | 2020-07-30 | 2020-09-06 | | 13 | 2020-07-31 | 2021-08-23 | | 14 | 2020-07-31 | 2021-11-04 | | 17 | 2020-08-04 | 2021-11-03 | | 18 | 2020-08-04 | 2021-10-22 | | 19 | 2020-08-05 | null | | 20 | 2020-08-05 | 2021-04-10 | | 21 | 2020-08-05 | 2021-10-28 | | 22 | 2020-08-10 | null | | 23 | 2020-08-10 | 2020-08-31 | | 23 | 2021-03-31 | 2021-04-01 | | 24 | 2020-08-10 | 2020-08-16 |
See SQL Fiddle for sample data (thanks to Isaac)
Explanation:
- In the first CTE (named 'base') we select the rows that form the start of a (potential) sequence. These rows don't have a proceeding row based on the rules specified in the OP. Each sequence gets a unique number assigned (ROW_NUMBER).
- In the second CTE (named 'walker') we recursively walk the sequence from start to end, assigning the sequence number to each row and preserving the last 'out' value.
- Finally, we select the MIN(in) and MAX(out) grouped by sequence number to get the desired results.