Suppose I have a company whose reporting relationships are given by:
ref_pd = pd.DataFrame({'employee':['a','b','c','d','e','f'],'supervisor':['c','c','d','f','f',None]})
e.g.
- a and b report to c, who reports to d, who reports to f
- e also reports to f
- f is the head and reports to no one
Is there a (clever) way to use
ref_pd- I know a priori that there are at most 4 "layers" to the company (f is layer 1, d and e are layer 2, c is layer 3, a and b are layer 4)
to compute the last column of:
gap_pd = pd.DataFrame({'supervisor':['d','d','d','d','d','d'],'employee':['a','b','c','d','e','f'],'gap':[2,2,1,0,None,None]})
The logic of this last column is like this: with the supervisor = d for each row
- if the employee = d, then that is also the supervisor, so there is no gap, so gap = 0
- c reports directly to d, so gap = 1
- a and b report to c, who reports to d, so gap = 2
- neither e nor f (eventually) reports to d, so gap is Null
The only thing I can think of is feeding ref_pd to a directed graph then computing path lengths but I struggle for a graph-less (and hopefully pure pandas) solution.
CodePudding user response:
Graph of the hierarchy:
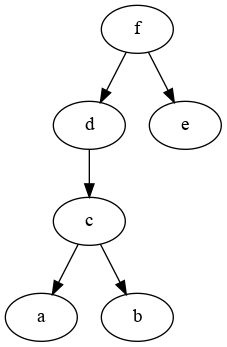
If is possible using iterative merges, but quite impractical:
target = 'd'
# set up containers
counts = pd.Series(index=ref_pd2['employee'], dtype=int)
valid = pd.Series(False, index=ref_pd['employee'])
# set up initial df2 for iterative merging
df2 = ref_pd.rename(columns={'employee': 'origin', 'supervisor': 'employee'})
# identify origin == target
valid[target] = True
counts[target] = 0
while df2['employee'].notna().any(): # or: for _ in range(4):
# increment count for non valid items
idx = valid[~valid].index
counts[idx] = counts[idx].add(1, fill_value=0)
# if we reached supervisor == target, set valid
m2 = df2['employee'].eq(target)
valid[df2.loc[m2, 'origin']] = True
# update df2
df2 = (df2.merge(ref_pd2, how='left')
.drop(columns='employee')
.rename(columns={'supervisor': 'employee'})
)
# set invalid items to NA
counts[~valid] = pd.NA
# craft output
gap_pd = pd.DataFrame({'supervisor': target,
'employee': ref_pd['employee'],
'gap': ref_pd['employee'].map(counts),
})
output:
supervisor employee gap
0 d a 2.0
1 d b 2.0
2 d c 1.0
3 d d 0.0
4 d e NaN
5 d f NaN
In comparison, a networkx solution is much more explicit:
import networkx as nx
G = nx.from_pandas_edgelist(ref_pd.dropna(),
source='supervisor', target='employee',
create_using=nx.DiGraph)
target = 'd'
gap_pd = ref_pd.assign(supervisor=target)
gap_pd['gap'] = [nx.shortest_path_length(G, target, n)
if target in nx.ancestors(G, n) or n==target else pd.NA
for n in ref_pd['employee']]
output:
employee supervisor gap
0 a d 2
1 b d 2
2 c d 1
3 d d 0
4 e d <NA>
5 f d <NA>