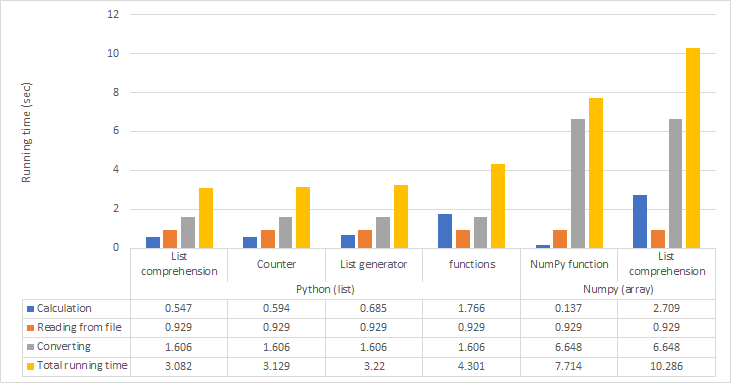
There is a list (price_list) of 10 million numbers as a price in range (0-100). I would like to do the following operations consequently:
- Filter the list with this condition (list_item < 30)
- Multiply each list_item with a fixed number (mapping)
- compute the sum of all elements (reduce)
Here is the sample code:
import time import numpy as np from functools import reduce with open('price_list.txt') as f: price_list = f.read().split('\n') price_list = np.array(price_list).astype(int) # convert string to int
I tried following options:
Using NumPy module (0.1069948673248291 seconds):
total = np.sum(price_list[price_list < 30] * 1.05)Using brute force loop (9.485718965530396 seconds)
Using filter, map, and reduce functions (10.078220844268799 seconds):
total = reduce(lambda x,y: x y,map(lambda x: x * 1.05, filter(lambda x: x < 30, price_list)) )Using list comprehension (8.609008073806763 seconds):
total= sum([x * 1.05 for x in price_list if x <30])Using generator (8.780538320541382 seconds):
total= sum((x * 1.05 for x in price_list if x <30))
It is obvious that the NumPy module is significantly fast in these operations. Is there any alternative solution for running this code faster using Python built-in functions and capabilities?
CodePudding user response:
Benchmark with three new solutions (starting from a list of strings as the one you got from your file):
4.1 s original_numpy
11.6 s original_listcomp
4.8 s better_listcomp
1.7 s even_better_listcomp
0.6 s counter
better_listcomp's only difference to yours is that I added .tolist(), so that price_list is actually a list and Python gets to work with Python ints instead NumPy ints, which is much faster. (Calling an array a list was really mislabeling).
even_better_listcomp goes a step further, never even going through NumPy at all. (And it multiplies with 1.05 just once, after adding.)
counter goes even further, delaying the conversion from string to int until after counting the price strings.
Code (