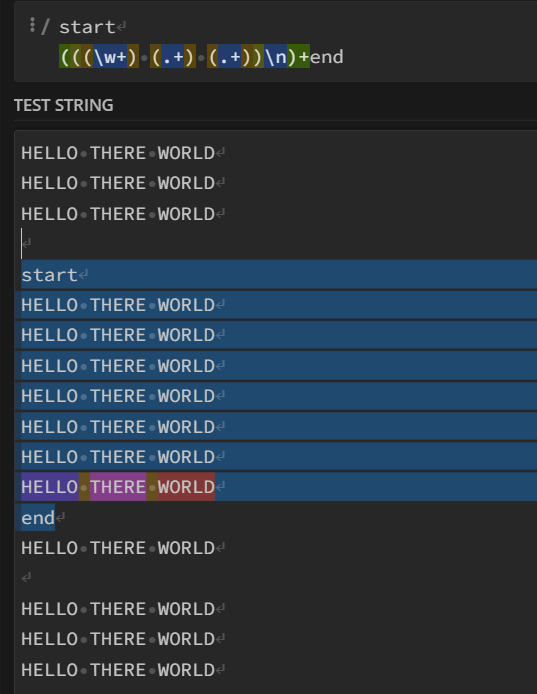
I want to capture the 'HELLO THERE WORLD' lines, but use the start and the end lines. However, it's just taking the last line.
regex: start\n(((\w ) (. ) (. ))\n) end
examples:
abcd 123 123
start
abcd 123 123
abcd 123 123
abcd 123 123
end
abcd 123 123
In the examples I want all the text between the start and the end to be In 3 groups for each line(group1=abcd,group2=123,group3=123)
like that:
CodePudding user response:
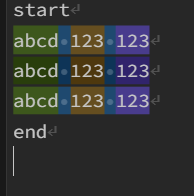
(?s)(?!.*?start)^(\w )\s(\w )\s(\w )(?=.*?end)
https://regex101.com/r/fDcMJd/1
CodePudding user response:
Try this regex:
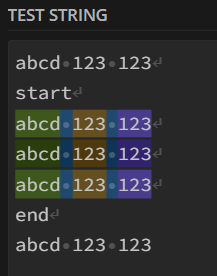
/(?<=start\n.*)(?:^([a-zA-Z] ) ([a-zA-Z] ) ([a-zA-Z] )$)(?=.*\nend)/gms
It should match every line with 3 words between start and end, and group those 3 words.
See example
CodePudding user response:
If you want to get all capture groups between start and end, you can make use of the Python PyPi regex module and the \G anchor to get consecutive matches.
(?:^start(?=(?:\n(?!start$|end$).*)*\nend$)|\G(?!^))\n(?!end\b)(\w )\s(\w )\s(\w )
Explanation
(?:Non capture group^startMatchstartat the start of the string(?=(?:\n(?!start$|end$).*)*\nend$)Assert that the wordendis present without crossing the wordstart|Or\G(?!^)Assert the position at the end of the previous match, not at the start of the string
)Close the non capture group\nMatch a newline(?!end\b)Negative lookahead, assert not the wordenddirectly to the right(\w )\s(\w )\s(\w )Capture group 1, 2 and 3 containing 1 or more word characters
See a Regex demo and a Python demo.