So I am doing Transfer Learning with tensorflow and I want to be able to run
history = model.fit(...) # Run initial training with base_model.trainable = False
After the first training is done, I can fine-tune it by unfreezing some layers so if the first session ran for 20 epochs my next block of code will be:
# Train the model again for a few epochs
fine_tune_epochs = 10
total_epochs = len(history.epoch) fine_tune_epochs
history_tuned = model.fit(train_set, validation_data = dev_set, initial_epoch=history.epoch[-1], epochs=total_epochs,verbose=2, callbacks=callbacks)
Basically it will take the epochs from history and will continue training from the last epoch and save these results in history_tuned
But I might want to train it again with more layers unfreezed so I would run history_tuned02 again and keep using the epochs for each history so my graphs look like one like the image below.
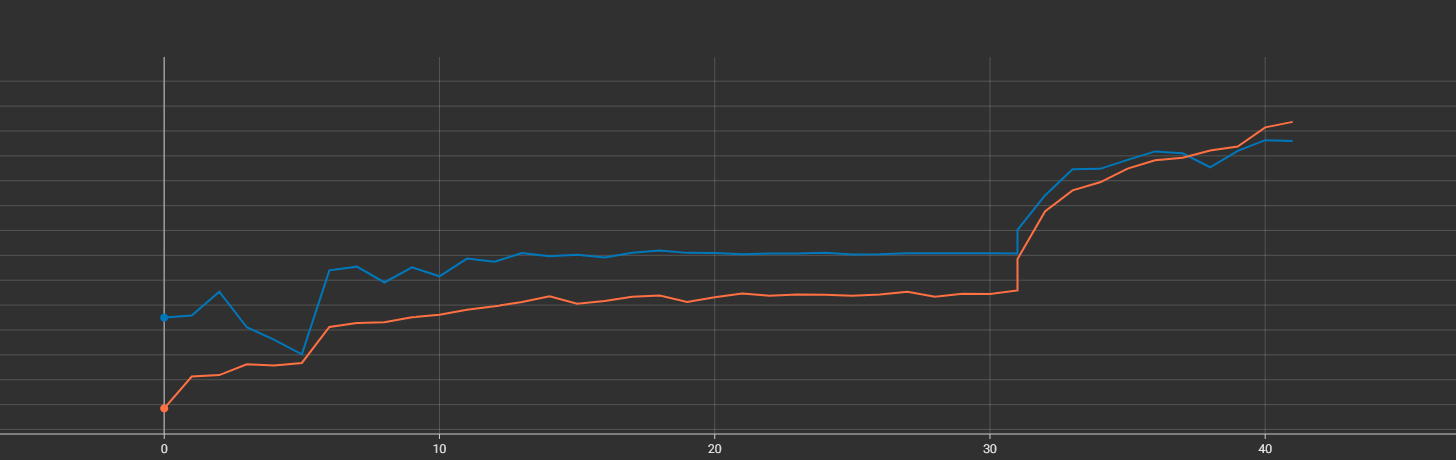
As you can see from the graph, it's all connected together but in reality is two different training sessions. The first one where the model is frozen and then the fine-tuned session. You can even tell where fine-tuning starts from the bump in performance.
The problem is, for me to do this I have to leave Jupyter open for days, because if I close it, all the variables are gone and I would need to train everything again, which would take insane amounts of time.
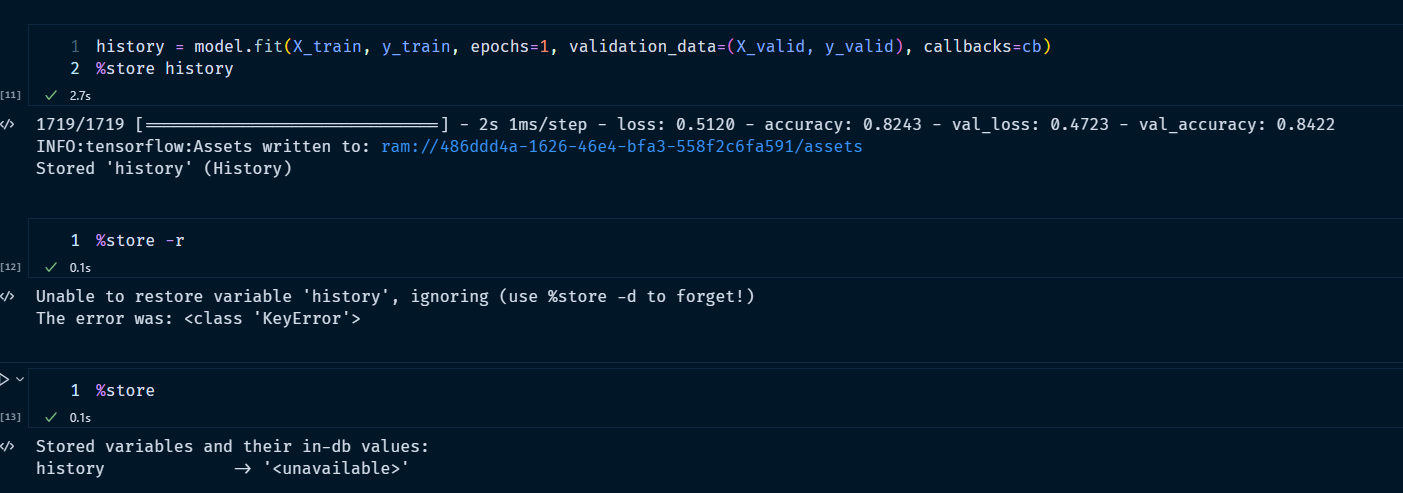
I tried using dill package but it would not work on history. I also tried using %store history but it also would not work for some reason as you can see from the image below on a dummy notebook that I test things.
So is there a way, to save history variable on disk, close jupyter, open it again, restore history and continue my work? Even if I leave jupyter and VS Code open until I finish with the model, crashes do happen.
Also I use checkpoint callback on tensorflow so I have my weights saved, restoring those is not a problem, but I do need history as well if it's possible.
UPDATE:
When I use CSVLogger callback as suggested and read it with
history = pd.read_csv('demo/logs/hist.log')
then
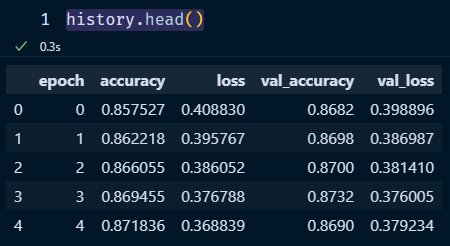
history.head()
The output is
CodePudding user response:
You can save your history in two ways:
The manual method:
Simply interrupt your training and save your history file as a dictionary:
with open('/history_dict', 'wb') as file:
pickle.dump(history.history, file)
You can then reload it with:
history = pickle.load(open('/history_dict'), "rb")
The automated method:
You can create a simple callback that every epoch stores your history. So, even if your training crashes, it was automatically saved and can be restored.
The callback can be something like this:
from tensorflow import keras
import tensorflow.keras.backend as K
import os
import csv
my_dir = './model_dir' # where to save history
class SaveHistory(keras.callbacks.Callback):
def on_epoch_end(self, batch, logs=None):
if ('lr' not in logs.keys()):
logs.setdefault('lr', 0)
logs['lr'] = K.get_value(self.model.optimizer.lr)
if not ('history.csv' in os.listdir(my_dir)):
with open(my_dir 'history.csv', 'a') as f:
content = csv.DictWriter(f, logs.keys())
content.writeheader()
with open(my_dir 'history.csv','a') as f:
content = csv.DictWriter(f, logs.keys())
content.writerow(logs)
model.fit(..., callbacks=[SaveHistory()])
To reload the history saved as a .csv simply do:
import pandas as pd
history = pd.read_csv('history.csv')
Also I think that besides the custom callback, you can also save the history along your model checkpoints with a CSVLogger like this:
history = model.fit(..., callbacks=[keras.callbacks.CSVLogger('history.csv')])
This can be loaded back with pandas as shown above.