I have to calculate in Python the number of unique active members by year, month, and group for a large dataset (N ~ 30M). Membership always starts at the beginning of the month and ends at the end of the month. Here is a very small subset of the data.
print(df.head(6))
0 member_id type start_date end_date
1 10 A 2021-12-01 2022-05-31
2 22 B 2022-01-01 2022-07-31
3 17 A 2022-01-01 2022-06-30
4 57 A 2022-02-02 2022-02-28
5 41 B 2022-02-02 2022-04-30
My current solution is inefficient as it relies on a for loop:
import pandas as pd
date_list = pd.date_range(
start=min(df.start_date),
end=max(df.end_date),
freq='MS'
)
members = pd.DataFrame()
for d in date_list:
df['date_filter'] = (
(d >= df.start_date)
& (d <= df.end_date)
)
grouped_members = (
df
.loc[date_filter]
.groupby(by='type', as_index=False)
.member_id
.nunique()
)
member_counts = pd.DataFrame(
data={'year': d.year, 'month': d.month}
index=[0]
)
member_counts = member_counts.merge(
right=grouped_members,
how='cross'
)
members = pd.concat[members, member_counts]
It produces the following:
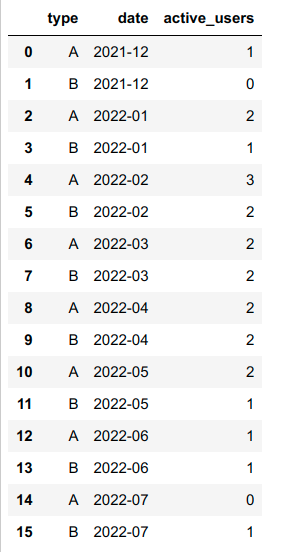
print(members)
0 year month type member_id
1 2021 12 A 1
2 2021 12 B 0
3 2022 1 A 3
4 2022 1 B 1
5 2022 2 A 3
6 2022 2 B 2
7 2022 3 A 2
8 2022 3 B 2
9 2022 4 A 2
10 2022 4 B 2
11 2022 5 A 2
12 2022 5 B 1
13 2022 6 A 1
14 2022 6 B 1
15 2022 7 A 0
16 2022 7 B 1
I'm looking for a completely vectorized solution to reduce computational time.
CodePudding user response:
You can try creating temporary column storing pd.date_range, exploding it and then do pd.crosstab:
df["range"] = df.apply(
lambda x: pd.date_range(x["start_date"], x["end_date"], freq="M"),
axis=1,
)
# exploding only two columns to save memory
df = (
pd.crosstab(
(x := df[["range", "type"]].explode("range"))["range"], x["type"]
)
.stack()
.to_frame("member_id")
.reset_index()
)
df["year"], df["month"] = (d := df.pop("range")).dt.year, d.dt.month
print(df[["year", "month", "type", "member_id"]])
Prints:
year month type member_id
0 2021 12 A 1
1 2021 12 B 0
2 2022 1 A 2
3 2022 1 B 1
4 2022 2 A 3
5 2022 2 B 2
6 2022 3 A 2
7 2022 3 B 2
8 2022 4 A 2
9 2022 4 B 2
10 2022 5 A 2
11 2022 5 B 1
12 2022 6 A 1
13 2022 6 B 1
14 2022 7 A 0
15 2022 7 B 1
CodePudding user response:
Here's an answer that works if each member_id is uinque. If an id comes up multiple times there may be a workaround...
The idea is to keep a running tally of the number of active users per type/month and add 1 to that tally the first time a member_id is seen, and subtract one after that same id is seen a second time
The months that are missing are ffill'ed after reindexing on all pairs of type/month
This should use less memory than exploding and crosstab. I think it should also be faster
The output format is slightly different than you specified
import itertools
#Create categorical index for reindexing later
groups = df.type.unique()
months = pd.date_range(
start=df.start_date.min(),
end=df.end_date.max(),
freq='MS',
).to_period('M')
cat_ind = pd.Categorical(itertools.product(groups,months))
#Convert the table to long form where start_date and end_date will be two separate rows for each member
df['end_date'] = pd.DateOffset(1) #push the end date to the next month
df['start_date'] = df.start_date.dt.to_period('M')
df['end_date'] = df.end_date.dt.to_period('M')
df = df.melt(
id_vars=['type','member_id'],
value_vars=['start_date','end_date'],
value_name='date',
).sort_values('date')
#Calculate number of active users
df['active_users'] = df.duplicated('member_id').multiply(-2).add(1).groupby(df.type).cumsum()
df = df.drop_duplicates(['type','date'],keep='last').drop(columns=['member_id','variable'])
#Reindex and ffill missing months
df = (
df.set_index(['type','date']).reindex(cat_ind)
.ffill().astype(int)
.reset_index()
.sort_values('date')
.reset_index(drop=True)
)
print(df)
Output