I want to remove all characters after 'r' in all of columns in dataframe. All columns of df are like this
1 311 889r/r 29.61%~sektor 21.56%
2 98 921r/r 218.42%~sektor 14.42%
3 NaN
4 37 215r/r 27.47%~sektor 11.80%
5 NaN
6 57 734r/r 5.28%~sektor -34.58%
7 89 883r/r -5.62%~sektor 2.74%
8 28 136r/r -7.12%~sektor 22.40%
9 385 084r/r 32.89%~sektor 32.89%
...
I'm trying to have only simple characters like:
1 311 889
2 98 921
3 NaN
4 37 215
Here are also dtypes of all my df columns
Unnamed: 0 object
2004 (gru 04) object
2005 (gru 05) object
2006 (gru 06) object
2007 (gru 07) object
2008 (gru 08) object
2009 (gru 09) object
2010 (gru 10) object
2011 (gru 11) object
2012 (gru 12) object
2013 (gru 13) object
2014 (gru 14) object
2015 (gru 15) object
2016 (gru 16) object
2017 (gru 17) object
2018 (gru 18) object
2019 (gru 19) object
2020 (gru 20) object
2021 (gru 21) object
2022/Q1 (mar 22) object
Unnamed: 20 float64
dtype: object
CodePudding user response:
Try Below code
import pandas as pd
import numpy as np
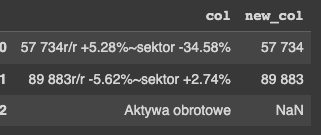
df = pd.DataFrame({'col':['57 734r/r 5.28%~sektor -34.58%', '89 883r/r -5.62%~sektor 2.74%', 'Aktywa obrotowe']})
df['new_col'] = df.col.str.split('[a-zA-Z].*', expand=True)[[0]].replace('',np.nan)
df
Output: