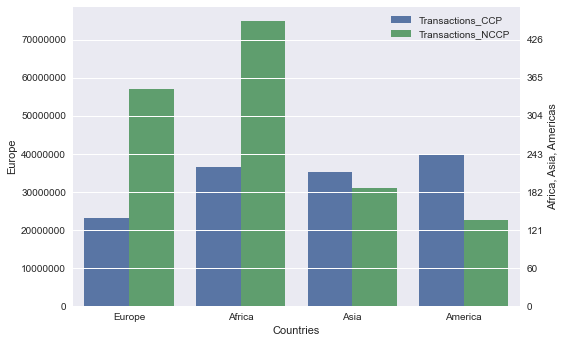
I have the following data that I want to plot as a stacked barplot. My problem is that I have a lot of transactions for Europe and not that many for the other countries. Therefore, I would like to plot a second axis with a different scale for all the other countries. I have seen that I can use the ax.twinx() command but all the examples I could find where when I want to have one variable with a different axis but I want to have one subcategory of a variable with a different axis.
How can I have one axis for the European countries and another axis for Africa, Asia and America?
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
matplotlib.style.use('seaborn')
df={'Countries':['Europe','Africa','Asia','America'],
'Transactions_CCP':[23000000,223,214,243],
'Transactions_NCCP':[57000000,456,189,137],
}
df = pd.DataFrame(df)
fig, ax = plt.subplots()
plt.bar(df["Countries"], df["Transactions_CCP"], label = "CCP")
plt.bar(df["Countries"], df["Transactions_NCCP"], bottom = df["Transactions_CCP"], label = "NCCP")
ax.legend(loc ="best")
CodePudding user response:
To do this, you need do the following
- Rearrange the data to enable easier plotting using melt
- Adjust the values of data for non-European countries so that they are on similar scale
- Plot the data and use two y-axes and adjust axis labels so that they are seen on left and right side
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
matplotlib.style.use('seaborn')
df={'Countries':['Europe','Africa','Asia','America'],
'Transactions_CCP':[23000000,223,214,243],
'Transactions_NCCP':[57000000,456,189,137],
}
df = pd.DataFrame(df)
#Melt the data... do print and see how the new data looks after melt
df=pd.melt(df, id_vars="Countries", var_name="CCP", value_name="value")
# Scale the data so that the average of Europe vs. non-Europe countries are used to determine the scale values
mask = df.Countries.isin(['Africa', 'Asia', 'America'])
scale = int(df[~mask].value.mean() / df[mask].value.mean())
# Mulitply non-European countries with scale
df.loc[mask, 'value'] = df.loc[mask, 'value']*scale
fig, ax = plt.subplots()
ax1=ax.twinx() #Two plots using ax and ax1 as axes
sns.barplot(x="Countries", y="value", hue="CCP", data=df, ax=ax)
# Give name and adjust how the Europe labels look
ax.set_ylabel('Europe')
ax.ticklabel_format(style='sci', axis='y', scilimits=(6,8))
# This is to set the y1 and y2 to the same positions, so that you see only one horizontal line
ax1.set_ylim(ax.get_ylim())
ax1.set_yticklabels((ax.get_yticks()/scale).astype(int))
ax1.set_ylabel('Africa, Asia, Americas')
ax.legend(loc ="best")
Plot