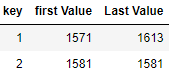I have a dataset which contain (index), key (product unique ID), datetime and values; there are 150K rows. Also it could be that some keys missed (i.e. len(key) may not work correctly):
index key Datetime Values
0 1 2019-05-03 11:16:18 1571.0
1 1 2019-05-03 11:25:53 1604.0
2 1 2019-05-03 11:29:11 1618.0
3 1 2019-05-03 11:30:01 1601.0
4 1 2019-05-03 11:30:39 1613.0
5 2 2019-05-03 11:37:27 1581.0
I need to drop all rows except first and last for each unique key and save first and last values to different columns. I understand that it need to be a function which define max and min values for datetime by key, append related values to two columns and drop all other values. However, I'm not able create workable function yet...
Can you please with it?
Many thanks for your help
CodePudding user response:
Assuming you only need key and Value in Output, Check below code if it helps.
Creating Data frame:
import pandas as pd
import numpy as np
import datetime as dt
data = {'index' : [0,1,2,3,4,5],\
'key' : [1,1,1,1,1,2],\
'Datetime' : ['03-05-2019 11:16:18','03-05-2019 11:25:53','03-05-2019 11:29:11','03-05-2019 11:30:01','03-05-2019 11:30:39','03-05-2019 11:37:27'],\
'Values' : [1571,1604,1618,1601,1613,1581]}
df=pd.DataFrame(data)
df['Datetime']= pd.to_datetime(df['Datetime'])
Code:
df=df.sort_values('Datetime')
df1=df.groupby("key").first().reset_index()
df2=df.groupby("key").last().reset_index()
df3=pd.merge(df1[['key','Values']],df2[['key','Values']],on='key',how='left')
df3.rename({"Values_x":"Min Value","Values_y":"Max Value"},inplace=True,axis=1)
Output: