df <- data.frame(
code1 = c ("ZAZ","ZAZ","ZAZ","ZAZ","ZAZ","ZAZ","JOZ","JOZ","JOZ","JOZ","JOZ","JOZ","TSV","TSV"),
code2 = c("NAN","NAN","NAN","NAN","NAN","NAN","NAN","NAN","NAN","NAN","NAN","NAN","TSA","TSA"),
start = c("Date1.1","Date1.1","Date1.3","Date1.3","Date1.5","Date1.5","Date3.1","Date3.1","Date3.3","Date3.3","Date3.5","Date3.5","Date 5.1","Date 5.1"),
end = c("Date2.1","Date2.1","Date2.3","Date2.3","Date2.5","Date2.5","Date4.1","Date4.1","Date4.3","Date4.3","Date4.5","Date4.5","Date6.1","Date6.1"),
price = c(1,2,3,4,5,6,1,2,3,4,5,6,1,2))
I'm trying to achieve:
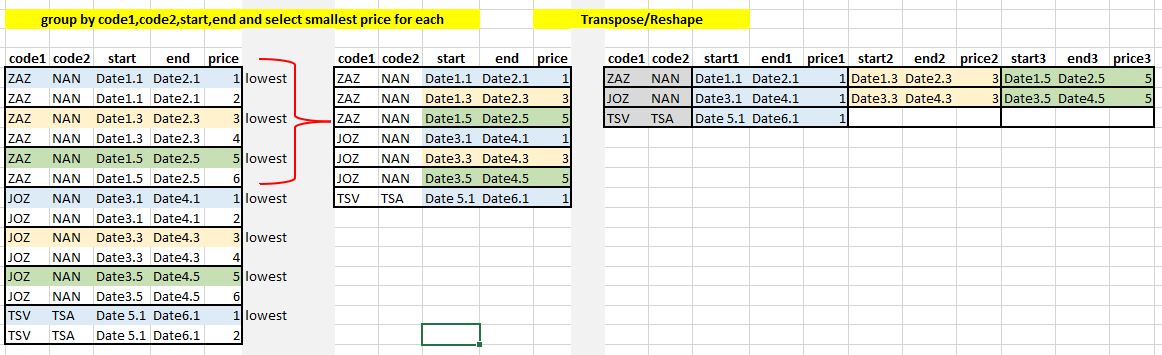
I have so far done:
df <- df %>%
group_by(code1, code2,start,end) %>%
slice_min(price) #%>%
group_modify()
df <- df[order(df$price),]
All well explained in the image but in brief:
- To group by code1,code2,start,end and select smallest price for each
- Reshape sending start,end,price to different columns (max 3 start,end,price per key code1,code2
- I understand that this can be done within group_modify() but unsure how
Any help so much appreciated! Brian
CodePudding user response:
Here is one way using dplyr and tidyr libraries.
- For each group (
code1,code2,startandend) calculate the minimum value ofprice. - Create an index column for
code1andcode2. This is to namestart,endandpriceasstart_1,start_2etc. - Get the data in wide format using
pivot_wider.
library(dplyr)
library(tidyr)
df %>%
group_by(code1, code2, start, end) %>%
summarise(price = min(price, na.rm = TRUE)) %>%
group_by(code1, code2) %>%
mutate(index = row_number()) %>%
ungroup() %>%
pivot_wider(names_from = index, values_from = c(start, end, price),
names_vary = "slowest")
# code1 code2 start_1 end_1 price_1 start_2 end_2 price_2 start_3 end_3 price_3
# <chr> <chr> <chr> <chr> <dbl> <chr> <chr> <dbl> <chr> <chr> <dbl>
#1 JOZ NAN Date3.1 Date4.1 1 Date3.3 Date4.3 3 Date3.5 Date4.5 5
#2 TSV TSA Date 5.1 Date6.1 1 NA NA NA NA NA NA
#3 ZAZ NAN Date1.1 Date2.1 1 Date1.3 Date2.3 3 Date1.5 Date2.5 5
Note that names_vary = "slowest" allows to have columns in an orderly fashion (start_1, end_1, price_1... instead of start_1, start_2 ..., end_1, end_2... etc. )
CodePudding user response:
I guess you can try aggregate reshape ave (all from base R)
reshape(
transform(
aggregate(price ~ ., df, min),
id = ave(seq_along(price), code1, code2, FUN = seq_along)
),
direction = "wide",
idvar = c("code1", "code2"),
timevar = "id"
)
which gives
code1 code2 start.1 end.1 price.1 start.2 end.2 price.2 start.3 end.3
1 ZAZ NAN Date1.1 Date2.1 1 Date1.3 Date2.3 3 Date1.5 Date2.5
4 JOZ NAN Date3.1 Date4.1 1 Date3.3 Date4.3 3 Date3.5 Date4.5
7 TSV TSA Date5.1 Date6.1 1 <NA> <NA> NA <NA> <NA>
price.3
1 5
4 5
7 NA