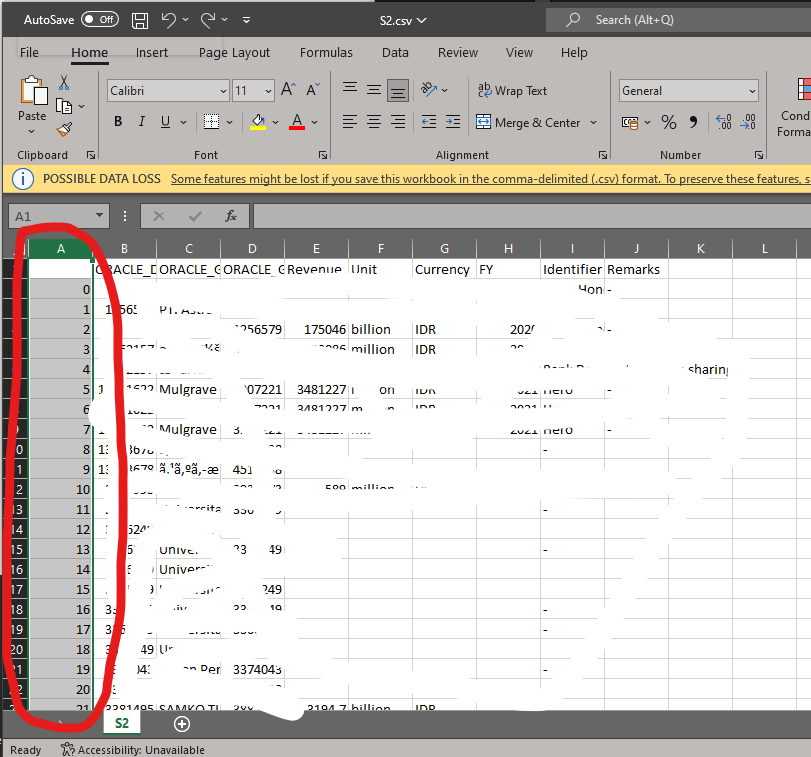
 I'm trying to extract each sheet in an Excel file into multiple CSVs.
For example Sheet1, Sheet2 and Sheet3 from Sample_1.xlsx into Sheet1.csv, Sheet2.csv and Sheet3.csv
The code I run is as below :
I'm trying to extract each sheet in an Excel file into multiple CSVs.
For example Sheet1, Sheet2 and Sheet3 from Sample_1.xlsx into Sheet1.csv, Sheet2.csv and Sheet3.csv
The code I run is as below :
import pandas as pd
dfs = pd.read_excel('Sample_1.xlsx', sheet_name=None)
for sheet_name, data in dfs.items():
data.to_csv(f"{sheet_name}.csv")
It outputs all of the three CSVs as desired but each csv has an extra column (column A) with index starting 0,1,2..n . Why is that happening? and How do I get rid of it?
CodePudding user response:
You need to specify the index parameter of pandas.DataFrame.to_csv as False
Replace :
data.to_csv(f"{sheet_name}.csv")
By :
data.to_csv(f"{sheet_name}.csv", index=False)