I have three different dataframes which all contain a column with certain IDs.
DF_1
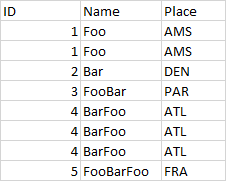
DF_2
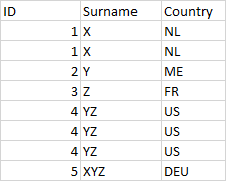
DF_3
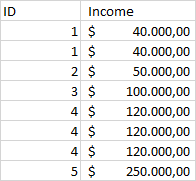
What I am trying to achieve is to create an Excel sheet with the ID as its name with the dataframes as the sheets 'DF_1, DF_2, DF_3' per unique value. So '1.xlsx' should contain three sheets (the dataframes) with only the records that are of associated with that ID. The thing I get stuck at is either getting the multiple sheets or only the corresponding values per unique value.
for name, r in df_1.groupby("ID"):
r.groupby("ID").to_excel(f'{name}.xlsx', index=False)
This piece of code gives me the correct output, but only for df_1. I get 5 Excel files with the corresponding rows per ID, but only one sheet, namely for df_1. I can't figure out how to include df_2 and df_3 per ID. When I try to use the following piece of code with nested loops, I get all the rows instead of per unique value:
writer = pd.ExcelWriter(f'{name}.xlsx')
r.to_excel(writer, sheet_name=f'{name}_df1')
r.to_excel(writer, sheet_name=f'{name}_df2')
r.to_excel(writer, sheet_name=f'{name}_df3')
writer.save()
There is more data transformation going on before this part, and the final dataframes are the once that are needed eventually. Frankly, I have no idea how to fix this or how to achieve this. Hopefully, someone has some insightful comments.
CodePudding user response:
Can you try the following:
unique_ids = df_1['ID'].unique()
for name in unique_ids:
writer = pd.ExcelWriter(f'{name}.xlsx')
r1 = df_1[df_1['ID'].eq(name)]
r1.to_excel(writer, sheet_name=f'{name}_df1')
r2 = df_2[df_2['ID'].eq(name)]
r2.to_excel(writer, sheet_name=f'{name}_df2')
r3 = df_3[df_3['ID'].eq(name)]
r.to_excel(writer, sheet_name=f'{name}_df3')
writer.save()