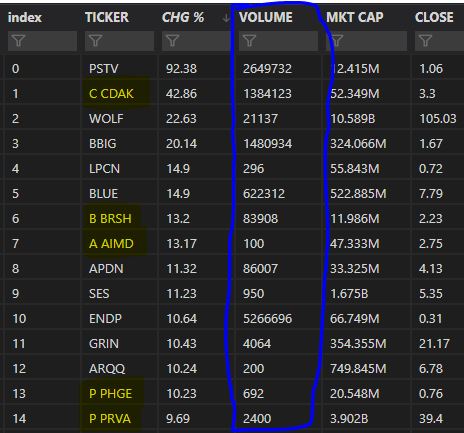
I want to format my "VOLUME" column the same way like the "MKT CAP" column with prefixes.
Prefixes like "M" for 10^6 or "k" for 10^3
I used the numerize library for this but need help to make it work for formatting the whole VOLUME column.
import pandas as pd
from numerize import numerize
df = pd.read_html('https://www.tradingview.com/markets/stocks-usa/market-movers-pre-market-gainers')[0]
df.columns =['TICKER', 'CLOSE', 'PRE-MKT CHG', 'CHG %', 'VOLUME', 'PRE-MKT GAP %', 'PRICE', 'CHG1 %', 'VOL', 'MKT CAP']
df = df.reindex(columns=['TICKER', 'CHG %', 'VOLUME', 'MKT CAP', 'CLOSE'])
df['VOLUME'] =df[numerize.numerize(df['VOLUME'])] #this line did not work
Also how can i filter out the first letter and space for only the yellow marked cells? There needs to be a filter looking for a space and also remove the first letter.
CodePudding user response:
The whitespace and first character can be filtered out by following line.
df['TICKER'] = df['TICKER'].str.replace('^.\s\s', '')
CodePudding user response:
For your numerize function try:
df['VOLUME'] = df['VOLUME'].apply(numerize.numerize)
For the string column, you can match using regex ^.\s to capture any single character followed by a space:
df['TICKER'] = df['TICKER'].str.replace('^.\s', '', regex=True)
If you have multiple whitespace characters after the first character you can do:
df['TICKER'] = df['TICKER'].str.replace('^.\s{1,}', '', regex=True)