I have a pandas dataframe as:
df_names = pd.DataFrame({'last_name':['Williams','Henry','XYX','Smith','David','Freeman','Walter','Test_A'],
'first_name':['Henry','Williams','ABC','David','Smith','Walter','Freeman','Test_B']})
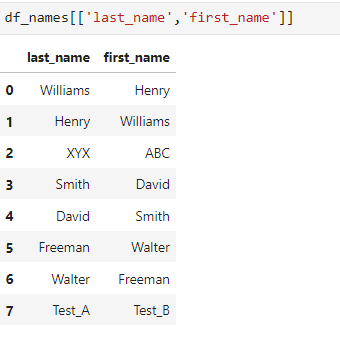
Here i have applied a frozen set on last_name and first_name columns to see if the names are interchanged i.e williams henry, henry williams.
df_names[['last_name','first_name']].apply(frozenset,axis=1)

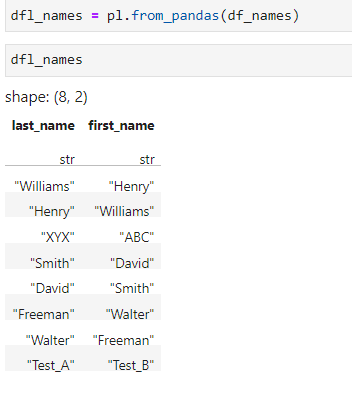
Here the same kind of implementation is required on polars dataframe. How to get it done ?
CodePudding user response:
As @ritchie46 mentioned, you'll want to avoid embedding Python objects (like frozensets) into a Polars DataFrame. The performance is not good, and columns of type object have limited functionality.
Here's a Polars algorithm that will be very performant and will accomplish what you need.
(
df_names
.with_column(
pl.concat_list([
pl.col("first_name").str.replace_all(r'\s','').str.to_uppercase(),
pl.col("last_name").str.replace_all(r'\s','').str.to_uppercase(),
])
.arr.sort()
.arr.join('|')
.alias('name_key')
)
.filter(pl.count().over('name_key') > 1)
)
shape: (6, 3)
┌───────────┬────────────┬────────────────┐
│ last_name ┆ first_name ┆ name_key │
│ --- ┆ --- ┆ --- │
│ str ┆ str ┆ str │
╞═══════════╪════════════╪════════════════╡
│ Williams ┆ Henry ┆ HENRY|WILLIAMS │
├╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ Henry ┆ Williams ┆ HENRY|WILLIAMS │
├╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ Smith ┆ David ┆ DAVID|SMITH │
├╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ David ┆ Smith ┆ DAVID|SMITH │
├╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ Freeman ┆ Walter ┆ FREEMAN|WALTER │
├╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ Walter ┆ Freeman ┆ FREEMAN|WALTER │
└───────────┴────────────┴────────────────┘
To help with matching, I've converted names to all uppercase and eliminated white space. (You can drop that if you don't find it useful.)
CodePudding user response:
dfl_names.apply (docs) will do. You'll need to wrap frozenset in tuple.