I am working with the following dataframe and want to generate columns with 'grandchildren'.
Parent Child
0 plant cactus
1 plant algae
2 plant tropical_plant
3 cactus aloe_vera
4 algae green_algae
5 tropical_plant monstrera
6 cactus blue_cactus
7 monstrera monkey_monstrera
8 blue_cactus light_blue_cactus
9 light_blue_cactus desert_blue_cactus_lightblue
I want my final dataframe to look like this:
plant | cactus | aloe vera
plant | cactus | blue cactus | light blue cactus | desert_blue_cactus_lightblue
plant | algea | green_algea
plant | tropical_plant | monstrera | monkey monstrera
I have gotten more and more confused about what is the cleanest way to do this in pandas. I wrote a function to extract 'grandchildren' and want to apply this to the last column of the df till the condition is met that there are no grandchildren left. The main question is what the best way of doing this would be. I am currently facing the following issues:
- I wrote a function find_grandchild(string), returning pandas.core.series.Series. If I use this function in apply, applying it to the last column of every row, I get a very strange result. I adjusted the function (below: find_grandchild_list(string) returning a list. Applying the new function to every row yields the result I want, but my column values are lists of lists. Since my function returns a list, I do not understand when and why these lists got wrapped in another list layer and how to rewrite my code to avoid this.
- Considering that some parents have more than one child (cactus:aloe vera, cactus:blue_cactus), I need to explode the new column after applying find_grandchild and before returning to the condition. Intuitively, I would do this in a while loop, but I am wondering if this is a bad practice as well, see code sketch below.
data = {'Parent':['plant','plant','plant','cactus','algae','tropical plant','cactus','monstrera','blue_cactus','light_blue_cactus']
'Child': ['cactus','algae','tropical_plant','aloe_vera','green_algae','monstrera','blue_cactus','monkey_monstrera','light_blue_cactus','desert_blue_cactus_lightblue']}
df = pd.DataFrame(data)
def find_grandchild(row):
grandchild_value = df.iloc[:,0] == row
return df[grandchild_value].iloc[:,-1]
def find_grandchild_list(row):
grandchild_value = df.iloc[:,0] == row
return [df[grandchild_value].iloc[:,-1]]
df.apply(lambda row : find_grandchild(row.iloc[-1]), axis=1)
df.apply(lambda row : find_grandchild_list(row.iloc[-1]), axis=1)
While sketch:
while any(df.iloc[:,-1].isin(df.iloc[:,-2])):
df = df.apply(lambda row : find_grandchild_list(row.iloc[-1]), axis=1) #currently not working bc of list problem
df = df.explode(iloc[:,-1])
CodePudding user response:
This is a graph problem that you can solve with 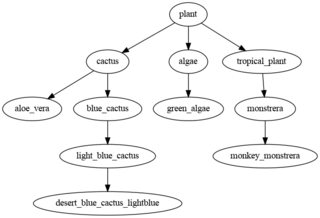
import networkx as nx
G = nx.from_pandas_edgelist(df, source='Parent', target='Child',
create_using=nx.DiGraph)
# find root
root = next(nx.topological_sort(G))
# find terminal nodes (also possible with networkx)
leafs = df.loc[~df['Child'].isin(df['Parent']), 'Child']
# generate all paths from root to terminal nodes
out = pd.DataFrame([nx.shortest_path(G, root, l) for l in leafs])
output:
0 1 2 3 4
0 plant cactus aloe_vera None None
1 plant algae green_algae None None
2 plant tropical_plant monstrera monkey_monstrera None
3 plant cactus blue_cactus light_blue_cactus desert_blue_cactus_lightblue