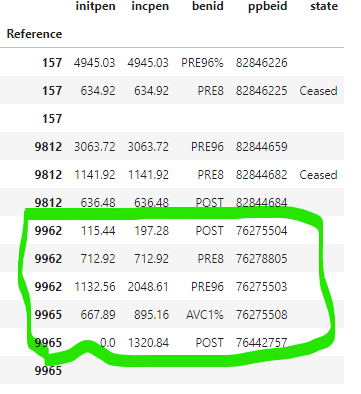
I have the following dataframe that I want to reshape:
Each row in Reference (my index) can have multiple rows in blocks of 'initpen', 'incpen', 'benid', 'ppbeid' and 'state' fields which go until the end of the dataframe. Oddly, in the very last column, I have an 'Unnamed' field which I drop from my dataframe in my code.
Once that is done, I then want to reshape the dataframe so each Reference has multiple rows with these blocks (the idea is get each Reference and only one block of 'initpen', 'incpen', 'benid', 'ppbeid' and 'state', with multiple rows - although I'm not sure if I should be setting the 'Reference' as the index at this point).
I have tried:
all_headers = list(dict.fromkeys(df.columns))
unique_headers = [x for x in all_headers if not "Unnamed" in x]
cols = len(unique_headers) - 2
df = df.drop(columns=df.filter(like='Unnamed').columns) # Drop the 'Unnamed' column
df = df.set_index(['Reference'])
# Below, I'm trying to reshape my dataframe
# and it's where I think it's not doing what I'm expecting
cols_per_id = len(df.columns) // cols
chunks = map(lambda k: df.iloc[:, k:k cols], range(0, cols_per_id, cols))
result = pd.concat(chunks, axis=0)
result = result.sort_index()
non_blanks = df[df.ppbeid != ""]
The issue I have is only one or two 'blocks' appear but misses off the rest of the 'blocks' but I'm not sure why.
I'm still in my very early days of using Python and Pandas so not entirely sure what I'm doing wrong. The code I have used thus far is a combination of my ideas and some other posts I've come across on StackOverflow, so any help would be greatly appreciated. Thanks in advance!
The result should look something like this:
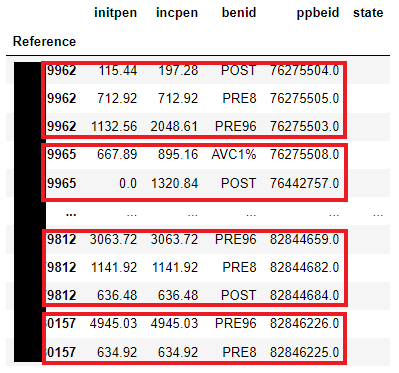
[EDIT]: Code to recreate above dataframe in the format I'm trying to figure out:
lst = [[9962, 115.44, 197.28, 'POST', 76275504, '',
712.92, 712.92, 'PRE8', 76278805, '',
1132.56, 2048.61, 'PRE96', 76275503, '',
'','','','',''],
[9965, 667.89, 895.16, 'AVC1%', 76275508, '',
0, 1320.84, 'POST', 76442757, '',
'','','','','',
'','','','',''],
[9812, 3063.72, 3063.72, 'PRE96', 82844659, '',
1141.92, 1141.92, 'PRE8', 82844682, 'Ceased',
636.48, 636.48, 'POST', 82844684, '',
'','','','',''],
[157, 4945.03, 4945.03, 'PRE96%', 82846226, '',
634.92, 634.92, 'PRE8', 82846225, 'Ceased',
'','','','','',
'','','','','']]
headers = ['Reference', 'initpen', 'incpen', 'benid', 'ppbeid', 'state',
'initpen', 'incpen', 'benid', 'ppbeid', 'state',
'initpen', 'incpen', 'benid', 'ppbeid', 'state',
'initpen', 'incpen', 'benid', 'ppbeid', 'state']
df = pd.DataFrame(lst, columns=headers)
df
CodePudding user response:
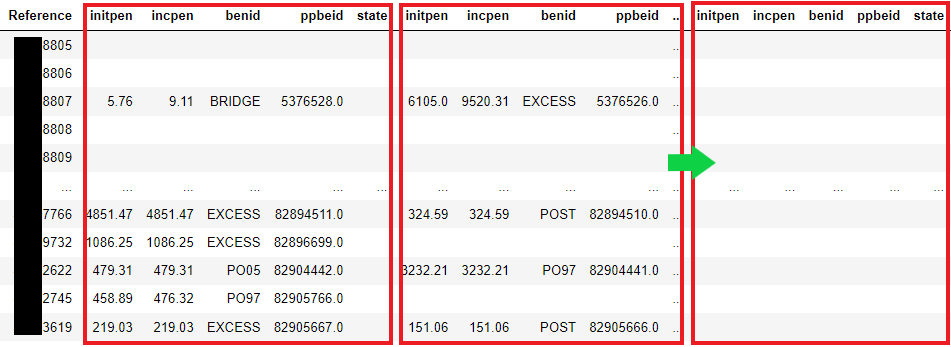
If you just want to reshape such that you want to have unique columns with index that can have multiple values, why not just slice the original df into two and concatenate that?
Here is a simple example: df
| W | X | Y | W | X | Y | |
|---|---|---|---|---|---|---|
| A | a | a | a | b | b | b |
| B | b | b | b | c | c | c |
| A | 1 | 1 | 1 | 2 | 2 | 2 |
| B | 2 | 2 | 2 | 3 | 3 | 3 |
df1 = df.iloc[:, :3 ]
df2 = df.iloc[:, 3:]
result = pd.concat([df1, df2], axis = 0)
result.sort_index(inplace = True)
print(result)
Output:
CodePudding user response:
Here, this should give you output as you wanted.
df.set_index("Reference", inplace=True)
df1 = df.iloc[:, :5 ]
df2 = df.iloc[:, 5:10 ]
df3 = df.iloc[:, 10:15 ]
result = pd.concat([df1, df2, df3], axis = 0)
result.sort_index(inplace = True)
result
Output: