User makes a selection inside of an HTML code in a web browser (rendered html).
Then I need to remove the text from the selection but keep the html tags.
Selection example:
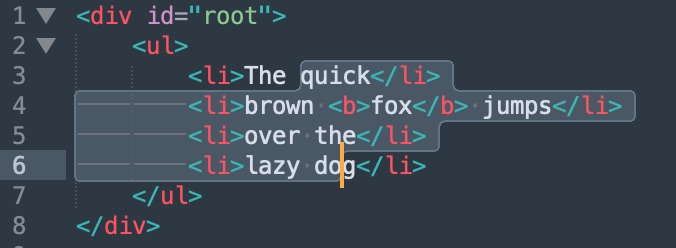
Desired output:
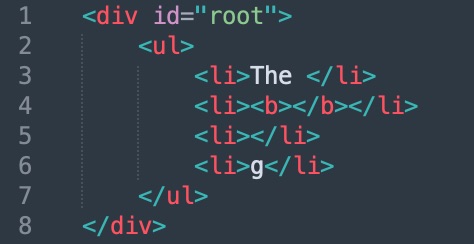
I can get the range via selection.getRangeAt(0) and therefore access the start / end nodes. I think I need to loop over the nodes between the start / end nodes but I can't figure out how; the start/end nodes are not necessarily siblings and this complicates the algorithm...
Any help would be much appreciated!
CodePudding user response:
Ok I have a working version of this. And I have to say it was a fun, challenging puzzle.
Basically this utilizes the built in method Selection.deleteFromDocument() Which does almost what you want, the problem is that it also will destroy any elements that are caught up in the selection as it gets deleted. So to solve for this I:
- Assign every dom elemnt a sequential unique id as a
data-*attribute. - Keep a snapshot of the dom in an array from before the
.deleteFromDocument()operation. - Take another picture of the dom after the deletion operation and create a list of DOM nodes that were removed by the
.deleteFromDocument()operation by comparing the two arrays. - Then with the list of elements that got the knife, loop through these and add them back using the awareness of their parent or previous sibling nodes (which are still findable via their unique id which I gave them).
- Remove their
innerTextbecause they retained it from before the delete operation. - Finally cleanup and remove the unique ids from all elements.
const button = document.querySelector("button");
let uniqueIdNumber = 0;
function uniqueId() {
uniqueIdNumber ;
return uniqueIdNumber;
}
button.addEventListener("click", () => {
const allElements = document.querySelectorAll("*");
allElements.forEach((element) =>
element.setAttribute("data-unique", uniqueId())
);
const originalDom = [...allElements].map((element) => ({
element: element,
uniqueId: element.getAttribute("data-unique"),
parent: element.parentElement?.getAttribute("data-unique"),
prev: element.previousElementSibling?.getAttribute("data-unique"),
}));
const selection = document.getSelection();
selection.deleteFromDocument();
const newAllElements = [...document.querySelectorAll("*")];
const newDom = newAllElements.map((element) =>
element.getAttribute("data-unique")
);
const removedElements = originalDom.filter(
(x) => !newDom.find((y) => x.uniqueId === y)
);
removedElements.forEach((record) => {
const prev =
record.prev &&
document.querySelector(`[data-unique="${record.prev}"]`);
if (prev) {
prev.insertAdjacentElement("afterend", record.element);
record.element.innerText = "";
} else {
const parent = document.querySelector(
`[data-unique="${record.parent}"]`
);
if (parent) {
parent.prepend(record.element);
record.element.innerText = "";
}
}
});
});
document.querySelectorAll("*").forEach((element) => {
element.removeAttribute("data-unique");
});<ul>
<li>The quick</li>
<li>brown fox</li>
<li>something something</li>
<li>the lazy dog</li>
</ul>
<button>Delete Selection</button>CodePudding user response:
You can first trim off the trailing unclosed text by using substring and getting the first occurrence of the tag starting character < and then getting the last occurrence of the tag ending character >.
Then, you can use a regex that matches all text within > ... <:
const selectedText = `
quick</li>
<li>brown <b>fox</b> jumps</li>
<li>over the</li>
<li>lazy do
`
const result = selectedText.substring(selectedText.indexOf('<'), selectedText.lastIndexOf('>') 1).replace(/(?<=>)(. ?)(?=<)/gm, '')
console.log(result)CodePudding user response:
You could remove the content between the html tags using javascript and alter the html that way. So you are left with an empty li.
items = document.querySelectorAll('li')
items.forEach(function(item) {
item.addEventListener('click', function(){
item.innerHTML = ''
if (item===items[1]) {
item.innerHTML = '<b></b>' // so 2nd still has the <b> tags
}
})
})<div id='root'>
<ul>
<li>The quick</li>
<li>brown <b>fox</b> jumps</li>
<li>over the</li>
<li>lazy dog</li>
</ul>
</div>