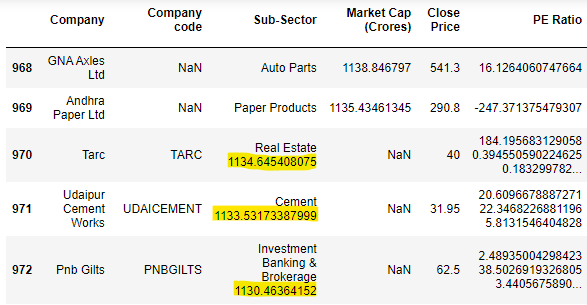
I am working on a share market data and in some columns market cap has shifted to previous column. I am trying to fetch them in next column but the value it's returning is completely different.
This is the code I am using -
data['Market Cap (Crores)']=data['Sub-Sector'].astype('str').str.extractall('(\d )').unstack().fillna('').sum(axis=1).astype(int)
data['Market Cap (Crores)']
But the output I am getting is
968 NaN
969 NaN
970 -2.147484e 09
971 -2.147484e 09
972 -2.147484e 09
How do I get the correct values?
CodePudding user response:
You just do it, step by step. First, pick out the rows that need fixing (where the market cap is Nan). Then, I create two functions, one to pull the market cap from the string, one to remove the market cap. I use apply to fix up the rows, and substitute the values into the original dataframe.
import pandas as pd
import numpy as np
data = [
['GNA Axles Ltd', 'Auto Parts', 1138.846797],
['Andhra Paper Ltd', 'Paper Products', 1135.434614],
['Tarc', 'Real Estate 1134.645409', np.NaN],
['Udaipur Cement Works', 'Cement 1133.531734', np.NaN],
['Pnb Gifts', 'Investment Banking 1130.463641', np.NaN],
]
def getprice(row):
return float(row['Sub-Sector'].split()[-1])
def removeprice(row):
return ' '.join(row['Sub-Sector'].split()[:-1])
df = pd.DataFrame( data, columns= ['Company','Sub-Sector','Market Cap (Crores)'] )
print(df)
picks = df['Market Cap (Crores)'].isna()
rows = df[picks]
print(rows)
df.loc[picks,'Sub-Sector'] = rows.apply(removeprice, axis=1)
df.loc[picks,'Market Cap (Crores)'] = rows.apply(getprice, axis=1)
print(df)
Output:
Company Sub-Sector Market Cap (Crores)
0 GNA Axles Ltd Auto Parts 1138.846797
1 Andhra Paper Ltd Paper Products 1135.434614
2 Tarc Real Estate 1134.645409 NaN
3 Udaipur Cement Works Cement 1133.531734 NaN
4 Pnb Gifts Investment Banking 1130.463641 NaN
Company Sub-Sector Market Cap (Crores)
2 Tarc Real Estate 1134.645409 NaN
3 Udaipur Cement Works Cement 1133.531734 NaN
4 Pnb Gifts Investment Banking 1130.463641 NaN
Company Sub-Sector Market Cap (Crores)
0 GNA Axles Ltd Auto Parts 1138.846797
1 Andhra Paper Ltd Paper Products 1135.434614
2 Tarc Real Estate 1134.645409
3 Udaipur Cement Works Cement 1133.531734
4 Pnb Gifts Investment Banking 1130.463641
CodePudding user response:
df['Sub-Sector Number'] = df['Sub-Sector'].astype('str').str.extractall('(\d )').unstack().fillna('').sum(axis=1).astype(int)
df['Sub-Sector final'] = df[['Sub-Sector Number','Sub-Sector']].ffill(axis=1).iloc[:,-1]
df
Hi there,
Here is the method which you can try, use your code to create a numeric field and select non-missing value from Sub-Sector Number and Sub-Sector creating your final field - Sub-Sector final
Please try it and if not working please let me know
Thanks Leon