The CSV files used in this code are air quality sensor data files. They record particle concentrations each hour over multiple years in some cases. There is about 100 CSV files I am using. I have already figured out how to look through each file and average a variable regardless of the year, but I am having trouble finding the averages for only the year 2020.
The goal of the code is to find the average number of hours each sensor is running in the year 2020.
# import modules
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import csv
# Read in table summarizing key variables about each Purple Air station around Pittsburgh
summary_table = pd.read_csv('Pittsburgh Hourly Averaged PM Data.csv')
# Subset the table to include only stations to be used in analysis
summary_table = summary_table[summary_table['Y/N'] == 'Y']
# Number of stations
print('Initial number of stations: ', len(summary_table))
num_hr = []
# Loop through all rows in the summary data table. For each row, find filename
# of the station corresponding to the row and read in that station data.
hours_utc = ['00','01','02','03','04','05','06','07','08','09','10','11','12','13','14','15','16','17','18','19','20','21','22','23']
for i in summary_table.index:
station_data = pd.read_csv('Hourly_Averages/Excel_Data/' summary_table.at[i,'Filename'] '.csv')
if station_data['year'] == 2020:
# num_hr.append(station_data['PM2.5_CF1_ug/m3'].mean())
station_data = station_data[station_data['hr'] == h]
print(num_hr)
with open('average_hr.csv', 'w') as f:
writer = csv.writer(f)
writer.writerow(num_hr)
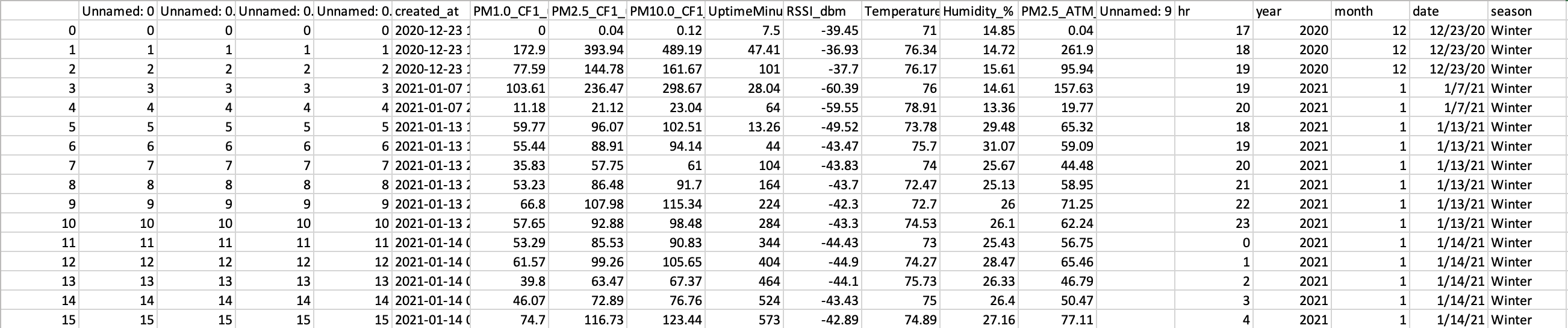
An example of the CSV's used by the code (the full CSV's are thousands of rows long and I don't know a way to put a full file in the question).
, Unnamed: 0, Unnamed: 0.1, Unnamed: 0.1.1, Unnamed: 0.1.1.1, created_at, PM1.0_CF1_ug/m3, PM2.5_CF1_ug/m3, PM10.0_CF1_ug/m3, UptimeMinutes, RSSI_dbm, Temperature_F, Humidity_%, PM2.5_ATM_ug/m3, hr, year, month, date, season
0 0 0 0 0 2020-12-23 17:00:00 UTC 0 0.04 0.12 7.5 -39.45 71 14.85 0.04 17 2020 12 12/23/20 Winter
1 1 1 1 1 2020-12-23 18:00:00 UTC 172.9 393.94 489.19 47.41 -36.93 76.34 14.72 261.9 18 2020 12 12/23/20 Winter
2 2 2 2 2 2020-12-23 19:00:00 UTC 77.59 144.78 161.67 101 -37.7 76.17 15.61 95.94 19 2020 12 12/23/20 Winter
3 3 3 3 3 2021-01-07 19:00:00 UTC 103.61 236.47 298.67 28.04 -60.39 76 14.61 157.63 19 2021 1 1/7/21 Winter
4 4 4 4 4 2021-01-07 20:00:00 UTC 11.18 21.12 23.04 64 -59.55 78.91 13.36 19.77 20 2021 1 1/7/21 Winter
5 5 5 5 5 2021-01-13 18:00:00 UTC 59.77 96.07 102.51 13.26 -49.52 73.78 29.48 65.32 18 2021 1 1/13/21 Winter

FYI I am fairly new to coding and using CSV files, there may be a simple answer to my question, but after looking over many sites I am still stuck. I appreciate any help any of you may have.
CodePudding user response:
Imagine this is your table :
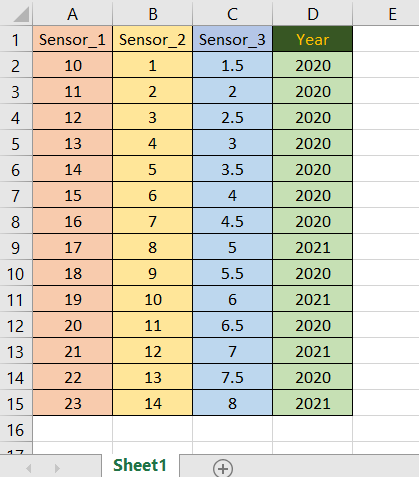
I tried to give you the idea on :
how to do something on a column on a condition of other column:
import pandas as pd
fields = ['Sensor_1','Sensor_2','Sensor_3','Year'] # you can tell pandas that fetch only these attributes
df = pd.read_excel('myData.xlsx' , usecols=fields)
sensor1 = df.Sensor_1.mean()
for x in df:
if(x != 'Year'):
sensor = df[x].where(df['Year'] == 2020).sum() / 14
print(sensor)
the result is :
10.785714285714286 # sensor_1 avg
4.357142857142857 # sensor_2 avg
2.892857142857143 # sensor_3 avg
For more :
I know after you read the code , you wonder is there any function to give you average, the answer is YES and the function name is mean() but when you use mean() it will ignore those rows that disabled in the condition (where(df['Year'] == 2020) ) so it will give you wrong result, for example in my sample it will give you the result of sum()/ 10 cause 4 rows are in 2021 Year.
This is all you need, just replace your attribute names with the code I gave you , I think it will help you .