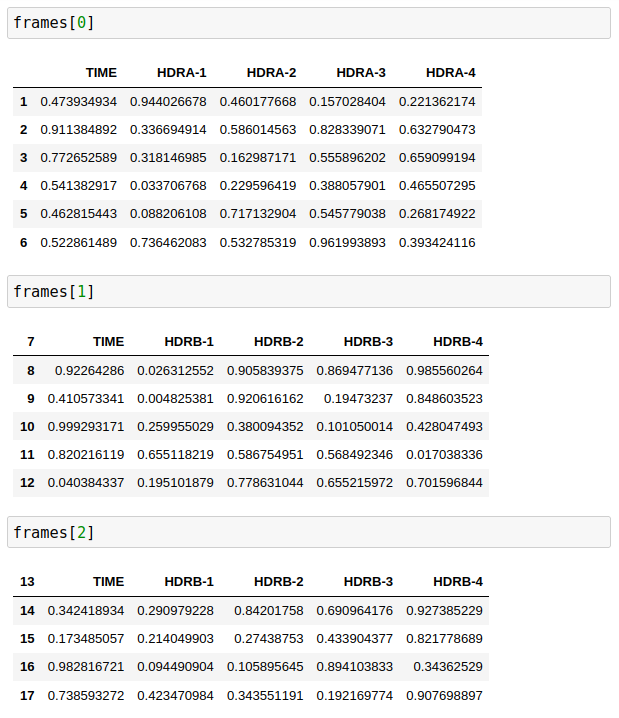
I have a CSV file that I have to do some data processing and it's a bit of a mess. It's about 20 columns long, but there are multiple datasets that are concatenated in each column. see dummy file below
I'm trying to import each sub file into a separate pandas dataframe, but I'm not sure the best way to parse the csv other than manually hardcoding importing a certain length. any suggestions? I guess if there is some way to find where the spaces are (I could loop through the entire file and find them, and then read each block, but that doesn't seem very efficient). I have lots of csv files like this to read.
import pandas as pd
nrows = 20
skiprows = 0 #but this only reads in the first block
df = pd.read_csv(csvfile, nrows=nrows, skiprows=skiprows)
Below is a dummy example:
TIME,HDRA-1,HDRA-2,HDRA-3,HDRA-4
0.473934934,0.944026678,0.460177668,0.157028404,0.221362174
0.911384892,0.336694914,0.586014563,0.828339071,0.632790473
0.772652589,0.318146985,0.162987171,0.555896202,0.659099194
0.541382917,0.033706768,0.229596419,0.388057901,0.465507295
0.462815443,0.088206108,0.717132904,0.545779038,0.268174922
0.522861489,0.736462083,0.532785319,0.961993893,0.393424116
0.128671067,0.56740537,0.689995486,0.518493779,0.94916205
0.214026742,0.176948186,0.883636252,0.732258971,0.463732841
0.769415726,0.960761306,0.401863804,0.41823372,0.812081565
0.529750933,0.360314266,0.461615009,0.387516958,0.136616263
TIME,HDRB-1,HDRB-2,HDRB-3,HDRB-4
0.92264286,0.026312552,0.905839375,0.869477136,0.985560264
0.410573341,0.004825381,0.920616162,0.19473237,0.848603523
0.999293171,0.259955029,0.380094352,0.101050014,0.428047493
0.820216119,0.655118219,0.586754951,0.568492346,0.017038336
0.040384337,0.195101879,0.778631044,0.655215972,0.701596844
0.897559206,0.659759362,0.691643603,0.155601111,0.713735399
0.860188233,0.805013656,0.772153733,0.809025634,0.257632085
0.844167809,0.268060979,0.015993504,0.95131982,0.321210766
0.86288383,0.236599974,0.279435193,0.311005146,0.037592509
0.938348876,0.941851279,0.582434058,0.900348616,0.381844182
0.344351819,0.821571854,0.187962046,0.218234588,0.376122331
0.829766776,0.869014514,0.434165111,0.051749472,0.766748447
0.327865017,0.938176948,0.216764504,0.216666543,0.278110502
0.243953506,0.030809033,0.450110334,0.097976735,0.762393831
0.484856452,0.312943244,0.443236377,0.017201097,0.038786057
0.803696521,0.328088545,0.764850865,0.090543472,0.023363909
TIME,HDRB-1,HDRB-2,HDRB-3,HDRB-4
0.342418934,0.290979228,0.84201758,0.690964176,0.927385229
0.173485057,0.214049903,0.27438753,0.433904377,0.821778689
0.982816721,0.094490904,0.105895645,0.894103833,0.34362529
0.738593272,0.423470984,0.343551191,0.192169774,0.907698897
0.021809601,0.406001002,0.072701623,0.964640184,0.023427393
0.406226618,0.421944527,0.413150342,0.337243905,0.515996389
0.829989793,0.168974332,0.246064043,0.067662474,0.851182924
0.812736737,0.667154845,0.118274705,0.484017732,0.052666038
0.215947395,0.145078319,0.484063281,0.79414799,0.373845815
0.497877968,0.554808367,0.370429652,0.081553316,0.793608698
0.607612542,0.424703584,0.208995066,0.249033837,0.808169709
0.199613478,0.065853429,0.77236195,0.757789625,0.597225697
0.044167285,0.1024231,0.959682778,0.892311813,0.621810775
0.861175219,0.853442735,0.742542086,0.704287769,0.435969078
0.706544823,0.062501379,0.482065481,0.598698867,0.845585046
0.967217599,0.13127149,0.294860203,0.191045015,0.590202032
0.031666757,0.965674812,0.177792841,0.419935921,0.895265056
TIME,HDRB-1,HDRB-2,HDRB-3,HDRB-4
0.306849588,0.177454423,0.538670939,0.602747137,0.081221293
0.729747557,0.11762043,0.409064884,0.051577964,0.666653287
0.492543468,0.097222882,0.448642979,0.130965724,0.48613413
0.0802024,0.726352481,0.457476151,0.647556514,0.033820374
0.617976299,0.934428994,0.197735831,0.765364856,0.350880707
0.07660401,0.285816636,0.276995238,0.047003343,0.770284864
0.620820688,0.700434525,0.896417099,0.652364756,0.93838793
0.364233925,0.200229902,0.648342989,0.919306736,0.897029239
0.606100716,0.203585366,0.167232701,0.523079381,0.767224301
0.616600448,0.130377791,0.554714839,0.468486555,0.582775753
0.254480861,0.933534632,0.054558237,0.948978985,0.731855548
0.620161044,0.583061202,0.457991555,0.441254272,0.657127968
0.415874646,0.408141761,0.843133575,0.40991199,0.540792744
0.254903429,0.655739954,0.977873649,0.210656057,0.072451639
0.473680525,0.298845701,0.144989283,0.998560665,0.223980961
0.30605008,0.837920854,0.450681322,0.887787908,0.793229776
0.584644405,0.423279153,0.444505314,0.686058204,0.041154856
CodePudding user response:
from io import StringIO
import pandas as pd
data ="""
TIME,HDRA-1,HDRA-2,HDRA-3,HDRA-4
0.473934934,0.944026678,0.460177668,0.157028404,0.221362174
0.911384892,0.336694914,0.586014563,0.828339071,0.632790473
0.772652589,0.318146985,0.162987171,0.555896202,0.659099194
0.541382917,0.033706768,0.229596419,0.388057901,0.465507295
0.462815443,0.088206108,0.717132904,0.545779038,0.268174922
0.522861489,0.736462083,0.532785319,0.961993893,0.393424116
TIME,HDRB-1,HDRB-2,HDRB-3,HDRB-4
0.92264286,0.026312552,0.905839375,0.869477136,0.985560264
0.410573341,0.004825381,0.920616162,0.19473237,0.848603523
0.999293171,0.259955029,0.380094352,0.101050014,0.428047493
0.820216119,0.655118219,0.586754951,0.568492346,0.017038336
0.040384337,0.195101879,0.778631044,0.655215972,0.701596844
TIME,HDRB-1,HDRB-2,HDRB-3,HDRB-4
0.342418934,0.290979228,0.84201758,0.690964176,0.927385229
0.173485057,0.214049903,0.27438753,0.433904377,0.821778689
0.982816721,0.094490904,0.105895645,0.894103833,0.34362529
0.738593272,0.423470984,0.343551191,0.192169774,0.907698897
"""
df = pd.read_csv(StringIO(data), header=None)
start_marker = 'TIME'
grouper = (df.iloc[:, 0] == start_marker).cumsum()
groups = df.groupby(grouper)
frames = [gr.T.set_index(gr.index[0]).T for _, gr in groups]