I want to add an extra column in a dataframe which displays the difference between certain rows, where the distance between the rows also depends on values in the table.
I found out that:
mutate(Col_new = Col_1 - lead(Col_1, n = x))
can find the difference for a fixed n, but only a integer can be used as input. How would you find the difference between rows for a varying distance between the rows?
I am trying to get the output in Col_new, which is the difference between the i and i n row where n should take the value in column Count. (The data is rounded so there might be 0.01 discrepancies in Col_new).
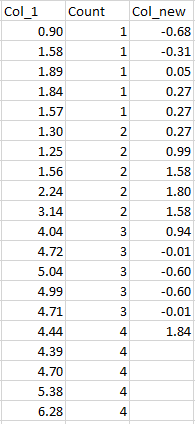
CodePudding user response:
df %>% mutate(Col_new = case_when(
df$count == 1 ~ df$col_1 - lead(df$col_1 , n = 1),
df$count == 2 ~ df$col_1 - lead(df$col_1 , n = 2),
df$count == 3 ~ df$col_1 - lead(df$col_1 , n = 3),
df$count == 4 ~ df$col_1 - lead(df$col_1 , n = 4),
df$count == 5 ~ df$col_1 - lead(df$col_1 , n = 5)
))
col_1 count Col_new
1 0.90 1 -0.68
2 1.58 1 -0.31
3 1.89 1 0.05
4 1.84 1 0.27
5 1.57 1 0.27
6 1.30 2 -0.26
7 1.25 2 -0.99
8 1.56 2 -1.58
9 2.24 2 -1.80
10 3.14 2 -1.58
11 4.04 3 -0.95
12 4.72 3 0.01
13 5.04 3 0.60
14 4.99 3 0.60
15 4.71 3 0.01
16 4.44 4 -1.84
17 4.39 4 NA
18 4.70 4 NA
19 5.38 4 NA
20 6.28 4 NA
This would give you your desired results but is not a very good solution for more cases. Imagine your task with 10 or more different counts another solution is required.
CodePudding user response:
Data:
df <- data.frame(Col_1 = c(0.90, 1.58, 1.89, 1.84, 1.57, 1.30, 1.35,
1.56, 2.24, 3.14, 4.04, 4.72, 5.04, 4.99,
4.71, 4.44, 4.39, 4.70, 5.38, 6.28),
Count = sort(rep(1:4, 5)))
Some code that generates the intended output, but can undoubtably be made more efficient.
library(dplyr)
df %>%
mutate(col_2 = sapply(1:4, function(s){lead(Col_1, n = s)})) %>%
rowwise() %>%
mutate(Col_new = Col_1 - col_2[Count]) %>%
select(-col_2)
Output:
# A tibble: 20 × 3
# Rowwise:
Col_1 Count Col_new
<dbl> <int> <dbl>
1 0.9 1 -0.68
2 1.58 1 -0.310
3 1.89 1 0.0500
4 1.84 1 0.27
5 1.57 1 0.27
6 1.3 2 -0.26
7 1.35 2 -0.89
8 1.56 2 -1.58
9 2.24 2 -1.8
10 3.14 2 -1.58
11 4.04 3 -0.95
12 4.72 3 0.0100
13 5.04 3 0.600
14 4.99 3 0.600
15 4.71 3 0.0100
16 4.44 4 -1.84
17 4.39 4 NA
18 4.7 4 NA
19 5.38 4 NA
20 6.28 4 NA