There are multiple posts on Stack Overflow with this theme but I have yet to find one in line with my issue. I have a dataset with patient shifts in a hospital and the list of nurses per shift, and I would like to create a new data frame that has one unique row for each shift with the nurse with the most patient contact from that shift (the patient contact variable is indicated by the variable 'ntotal'). In the event that there are two nurses during a shift that have the same ntotal maximum value, I just want to select one name, and it can be based on alphabetical order, e.g. taking the last name that comes first in the alphabet.
So for example I have this:
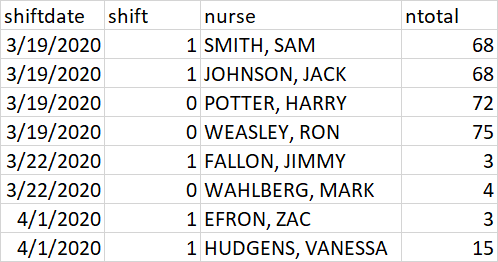
I want this:
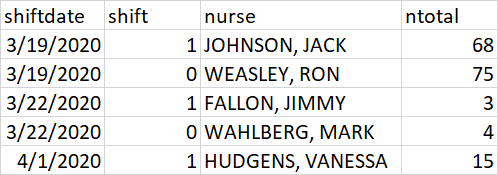
I ran this code:
have<-original %>%
select(MRN, encounter_id, shiftdate, shift, nurse, ntotal)%>%
group_by(MRN, encounter_id, shiftdate, shift)%>%
filter(ntotal==max(ntotal), nurse==first(nurse))
But I got this instead:

Where am I going wrong? Is there a way to do this differently using dplyr and/or tidyr? I realize I could do this using sqldf, but I would rather avoid that because I later am inserting my dataframe into a loop and sqldf was creating some formatting and length issues in the dataframe that was resulting in error messages when I tried to run the loop. Thank you!
Also here is some reproducible data:
MRN<-c(100,100,100,100,200,200,300,300)
encounter_id<-c(100, 100, 100, 100, 125, 125, 300, 300)
shiftdate<-c("2020-19-03", "2020-19-03", "2020-19-03", "2020-19-03", "2020-22-03", "2020-22-03", "2020-01-04", "2020-01-04")
shiftdate = as.Date(shiftdate, "%Y-%d-%m")
shift<-c(1, 1, 0, 0, 1, 0, 1, 1)
nurse<-c("SMITH, SAM", "JOHNSON, JACK", "POTTER, HARRY", "WEASLEY, RON", "FALLON, JIMMY", "WAHLBERG, MARK", "EFRON, ZAC", "HUDGENS, VANESSA")
ntotal<-c(68, 68, 72, 75, 3, 4, 3, 14)
original<-data.frame(MRN, encounter_id, shiftdate, shift, nurse, ntotal)
CodePudding user response:
with dplyr:
original %>%
arrange(shiftdate, shift, nurse) %>%
group_by(shiftdate, shift) %>% slice_max(ntotal, n = 1, with_ties = FALSE)
and with data.table just because ;)
library(data.table)
setDT(original)
original[order(shiftdate, -shift, nurse),
.SD[which.max(ntotal)],
by = .(shiftdate, shift)]