I tought using Transpose but it doesn't work, Please help, I have this input dataframe
number
1
2
3
4
6
And i need this Output
number C1 C2 C3 C4 C5 C6
1 1 nan nan nan nan nan
2 1 2 nan nan nan nan
3 1 2 3 nan nan nan
4 1 2 3 4 nan nan
6 1 2 3 4 5 6
CodePudding user response:
I solved my own question, i post my solution here it will surely help someone.
max=df1["number"].max()
for i in range(1,max 1):
df1["column" str(i)]=np.where(df1["number"] >=(i) , i, np.nan)
CodePudding user response:
Try this:
(df.join(pd.DataFrame(
df['number']
.map(lambda x: range(1,x 1)).tolist())
.rename(lambda x: 'C{}'.format(x 1),axis=1)))
Output:
number C1 C2 C3 C4 C5 C6
0 1 1 NaN NaN NaN NaN NaN
1 2 1 2.0 NaN NaN NaN NaN
2 3 1 2.0 3.0 NaN NaN NaN
3 4 1 2.0 3.0 4.0 NaN NaN
4 6 1 2.0 3.0 4.0 5.0 6.0
CodePudding user response:
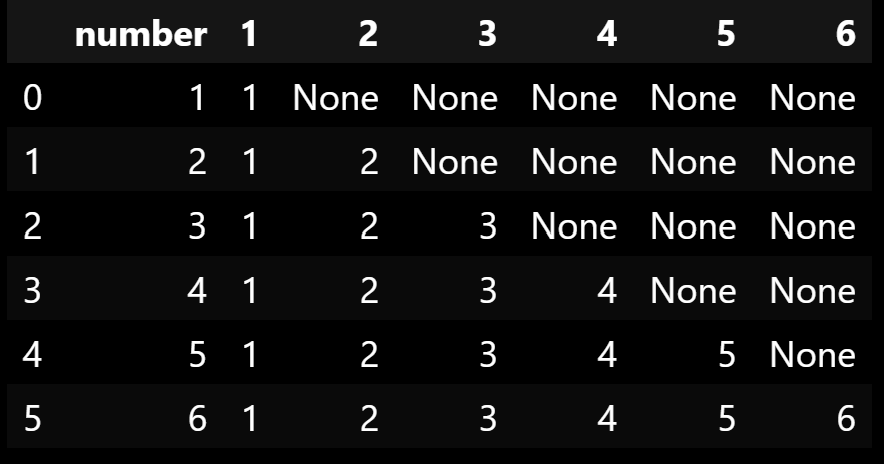
Welcome to StackOverflow!
import pandas as pd
# Creates the DF
input_df = pd.DataFrame([1, 2, 3, 4, 5, 6], columns=['number'])
# Creates a list from the values in the 'number' column
values_in_column = input_df.number.tolist()
# For each values in our list, create a column in the DF
for val in values_in_column:
input_df[val] = None
# For each row in the input DF:
for index, row in input_df.iterrows():
# Iterate over each column (except the first one)
for col_val in input_df.columns[1:]:
# If the value in 'number' at this row is greater of equal to the value of the column header
if row['number'] >= col_val:
# Enter the value of the column into the DF
input_df.at[index, col_val] = col_val
This should do what you're looking for. Note, when I make the dataframe, the column headers are integers and not strings like in your question ('C1', 'C2', etc.).