I'm creating a pipeline on ADF and basically I've 2 variables and 1 object.
The variables are arrays:
- CountryPartition: https://i.stack.imgur.com/7k1hm.png
- YearPartition: https://i.stack.imgur.com/r4B2o.png
{kind=link}
{kind=link}
And I've a lookup activity that I'm querying a azure storage table to get more parameters: https://i.stack.imgur.com/a5Csv.png
{kind=link}
I want to append dynamically the CountryPartition, YearPartition and databricksPath and pass to foreach activity. For that example and following the parameters it will run 16 times. 2 different databricks paths for 4 countries and 2 years: https://i.stack.imgur.com/jqlLs.png
{kind=link}
I tried to create this solution @union(activity('Config Table Synapse Fact Query').output.value, array(concat('{"countryPartition" :',variables('CountryPartition'),'}')), array(concat('{"yearPartition" :',variables('YearsPartition'),'}')))
and I obtained this result: https://i.stack.imgur.com/ypytv.png
{kind=link}
but when I tried to pass this result to Foreach activity it got a error: https://i.stack.imgur.com/w1PIn.png
{kind=link}
Foreach activity: https://i.stack.imgur.com/exRka.png
{kind=link}
Details The expression 'item().countryPartition' cannot be evaluated because property 'countryPartition' doesn't exist, available properties are 'PartitionKey, RowKey, Timestamp, ID, databricksPath, databricksTable, onOff, synapseTable, tableType'.
It seems that it only considers the values in the first json and not the other variables (countryPartition and yearPartition)
Can anyone please help me in achieving this
Thank you!
CodePudding user response:
The error is because, you applied @union and combined strings to an array of objects (concat('{"countryPartition" :',variables('CountryPartition'),'}') is a string).
- To overcome the error you can use the following (convert the above string to json):
@union(activity('Config Table Synapse Fact Query').output.value, array(json(concat('{"countryPartition" :',variables('CountryPartition'),'}'))), array(json(concat('{"yearPartition" :',variables('YearsPartition'),'}'))))
- But this does not help to get the 16 combinations of databricks path, country partition and year partition. You would have to use multiple loops to get all the required combinations (as in image 4).
- Instead, you can utilize dataflows to get the required result. You can follow the procedure given below.
- We already have 2 array variables for
countryPartition and yearPartition(I took these as array parameters for demo). Now I used afor eachactivity along withappend variableactivity (which is inside for each.) to get an array of databricks paths.

- Now, I need to pass
paths, countryPartition, yearPartitionarrays to dataflow, where I obtain the combination of each (16 combinations as in image 4).
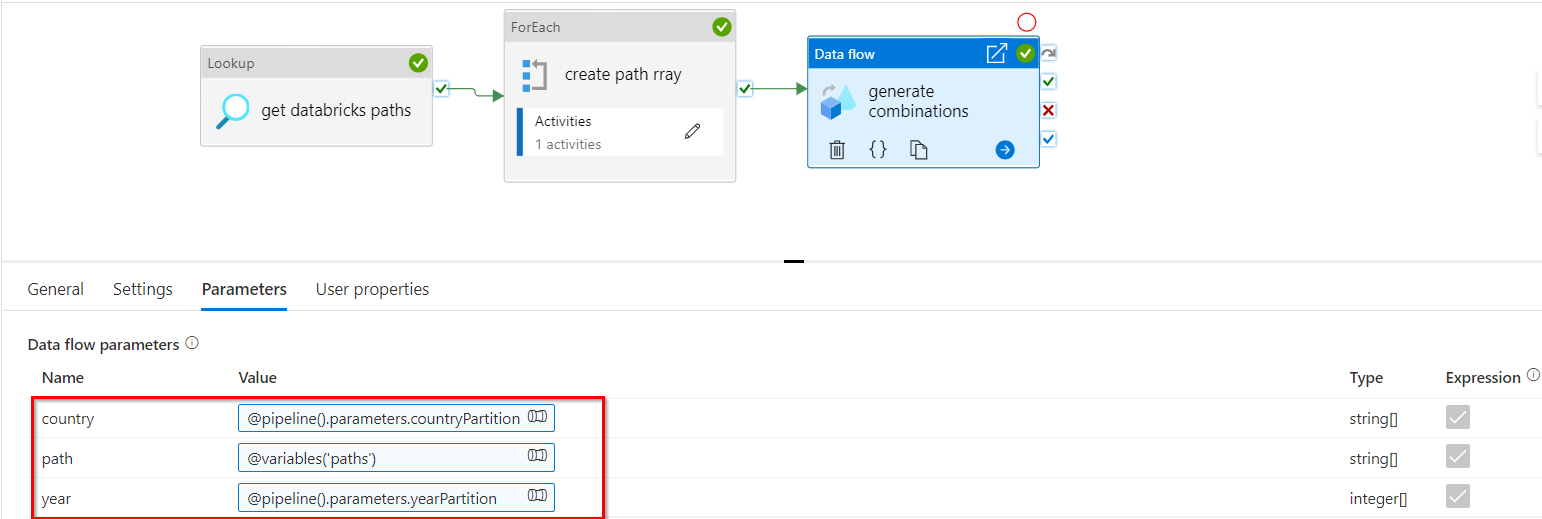
Inside my dataflow, I have taken a sample source file with just one row (this file is used only to achieve what we want. Data in this file does not affect the process).
Create 3 sources with this sample file. Apply
derived columntransformation on each of the source. For source 1, I added country column with value asunfold($country). Similarly for source 2 (path column with value asunfold($path)) and source 3 (year column with value asunfold($year)).
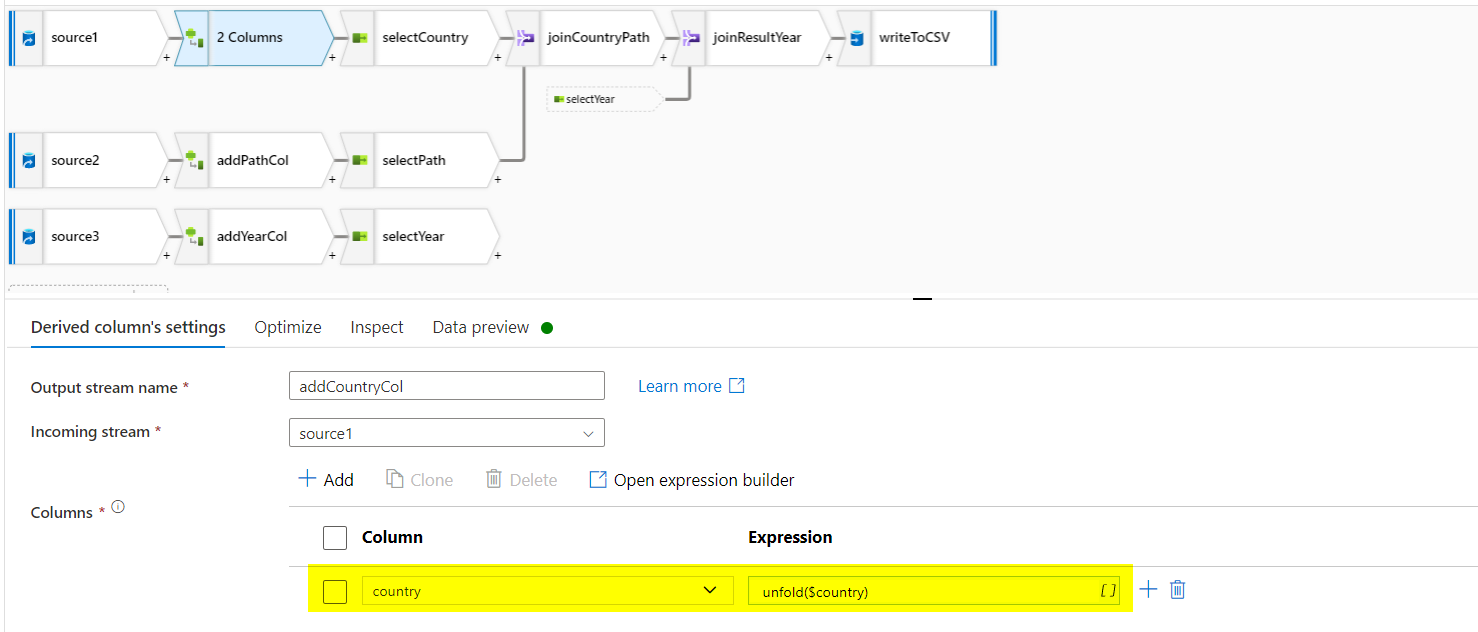
- Use select on each of the above only to select the required column (country, path and year respectively).
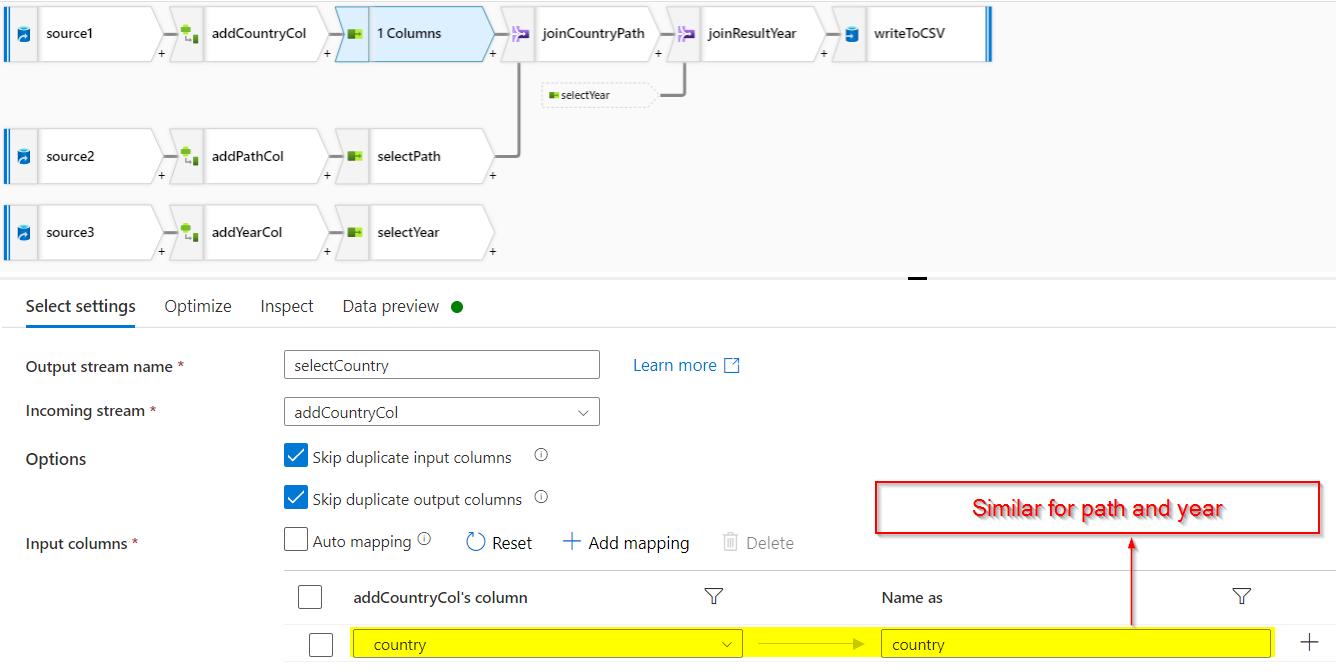
- Now we have 3 tables each containing one required column. You can apply
jointransformation (custom cross join with condition astrue()). Use cross join on tables containing country and path. Then apply cross join on the result of above and year table.
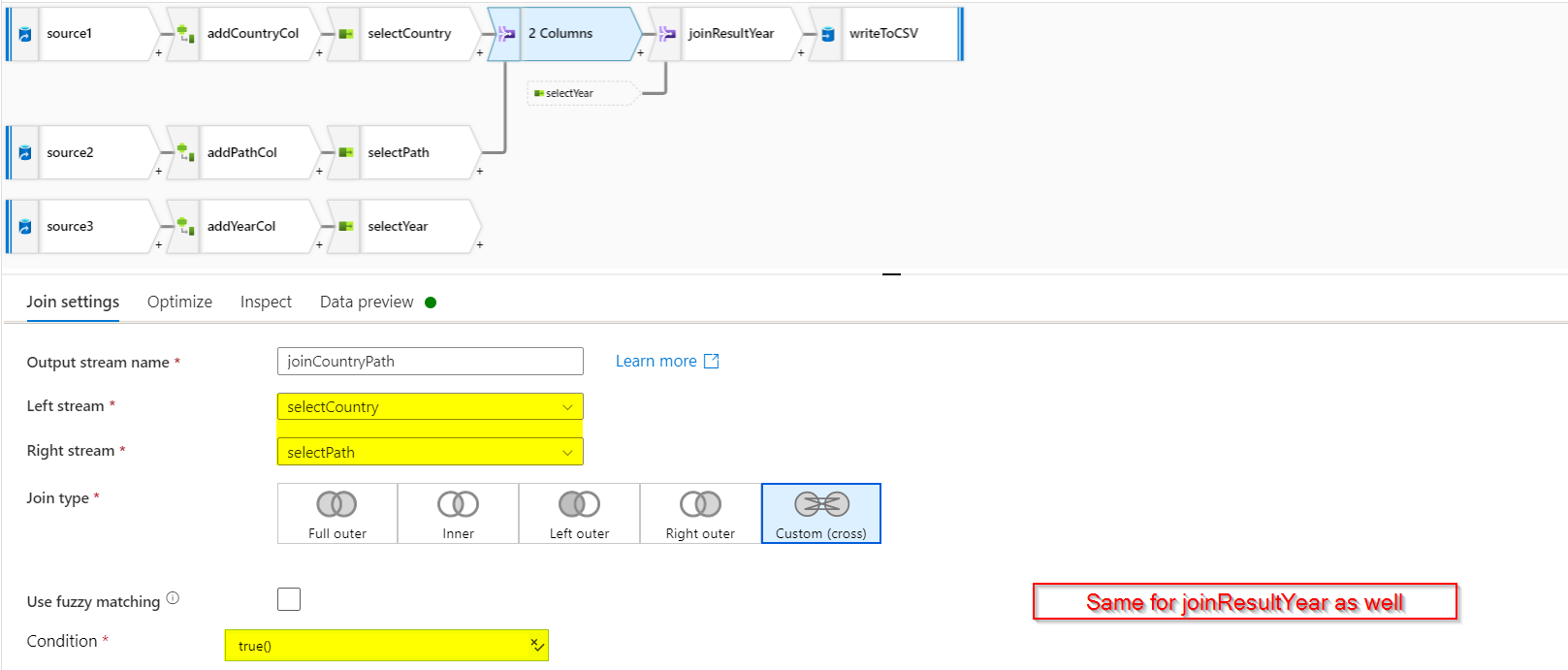
Select sink as your storage account (in
writeToCSV). The required result will be written to your sink as a csv file. The following is the debug output: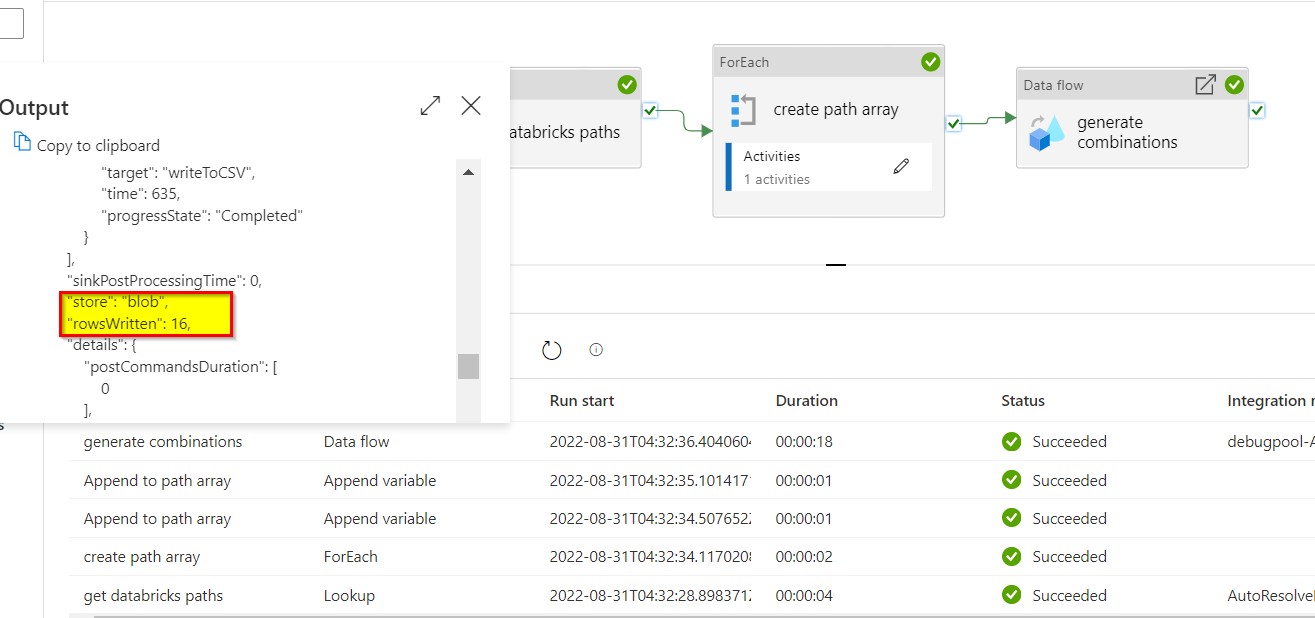
The following is an image of resultant CSV file with required records:
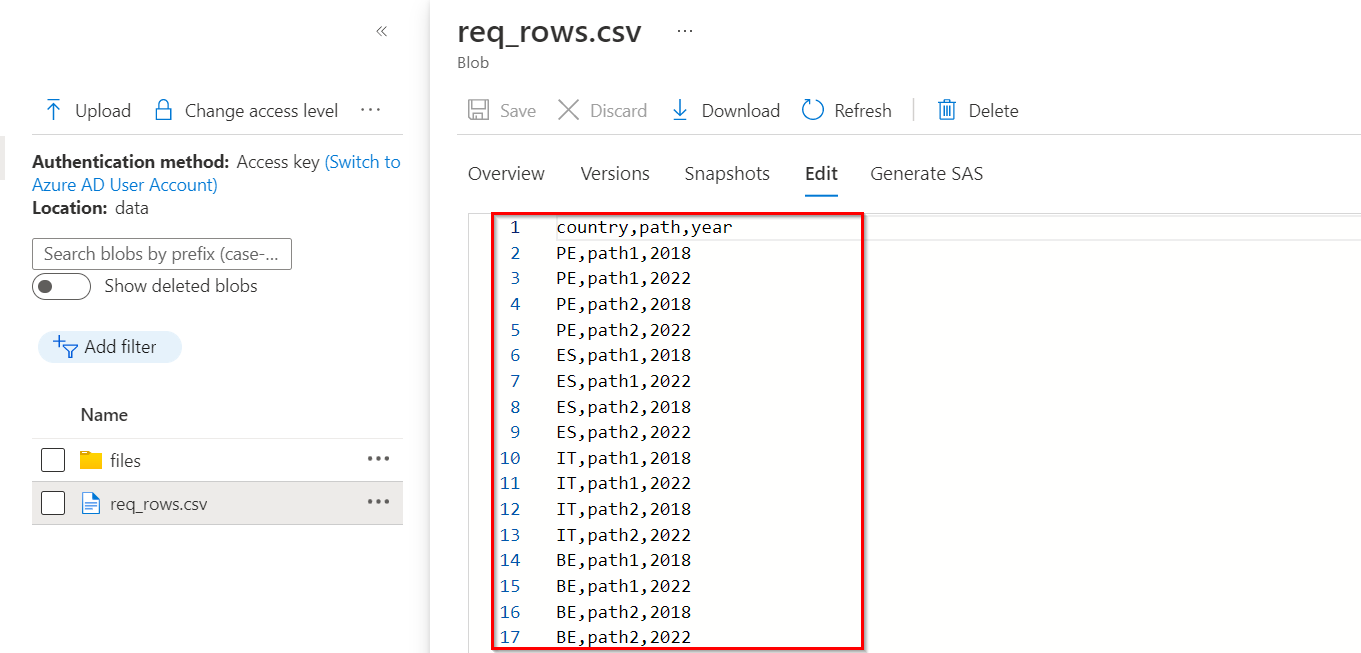
Now you can use lookup to read this req_rows.csv file. You can pass @activity('Lookup req csv').output.value as items in for each. Inside this you can pass the path, yearPartition and countryPartition values as @item().path , @item().country, @item().year from your databricks notebook activity.