I have a json file which looks something like this:
{"customer": 10, "date": "2017.04.06 12:09:32", "itemList": [{"item": "20126907_EA", "price": 1.88, "quantity": 1.0}, {"item": "20185742_EA", "price": 0.99, "quantity": 1.0}, {"item": "20138681_EA", "price": 1.79, "quantity": 1.0}, {"item": "20049778001_EA", "price": 2.47, "quantity": 1.0}, {"item": "20419715007_EA", "price": 3.33, "quantity": 1.0}, {"item": "20321434_EA", "price": 2.47, "quantity": 1.0}, {"item": "20068076_KG", "price": 28.24, "quantity": 10.086}, {"item": "20022893002_EA", "price": 1.77, "quantity": 1.0}, {"item": "20299328003_EA", "price": 1.25, "quantity": 1.0}], "store": "825f9cd5f0390bc77c1fed3c94885c87"}
I read it using this code :
transaction_df = spark \
.read \
.option("multiline", "true") \
.json("../transactions.txt")
Output I have :
-------- ------------------- ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- --------------------------------
|customer|date |itemList |store |
-------- ------------------- ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- --------------------------------
|10 |2017.04.06 12:09:32|[{20126907_EA, 1.88, 1.0}, {20185742_EA, 0.99, 1.0}, {20138681_EA, 1.79, 1.0}, {20049778001_EA, 2.47, 1.0}, {20419715007_EA, 3.33, 1.0}, {20321434_EA, 2.47, 1.0}, {20068076_KG, 28.24, 10.086}, {20022893002_EA, 1.77, 1.0}, {20299328003_EA, 1.25, 1.0}]|825f9cd5f0390bc77c1fed3c94885c87|
-------- ------------------- ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- --------------------------------
Output I am looking for :
-------- --------------
|customer| itemList|
-------- --------------
| 10| 20126907_EA|
| 10| 20185742_EA|
| 10| 20138681_EA|
| 10|20049778001_EA|
| 10|20419715007_EA|
| 10| 20321434_EA|
| 10| 20068076_KG|
| 10|20022893002_EA|
| 10|20299328003_EA|
-------- --------------
Basically I am looking for customer and number of items (10 for customer id and its respective purchased item)
CodePudding user response:
You could explode the array and select an item for each row.
Example:
from pyspark.sql import SparkSession
from pyspark.sql import functions as F
spark = SparkSession.builder.getOrCreate()
df = spark.read.json("test.json", multiLine=True)
df = df.withColumn("tmp", F.explode_outer("itemList"))
df = df.select(["customer", "tmp.item"])
df.show(10, False)
df.printSchema()
Output:
-------- --------------
|customer|item |
-------- --------------
|10 |20126907_EA |
|10 |20185742_EA |
|10 |20138681_EA |
|10 |20049778001_EA|
|10 |20419715007_EA|
|10 |20321434_EA |
|10 |20068076_KG |
|10 |20022893002_EA|
|10 |20299328003_EA|
-------- --------------
root
|-- customer: long (nullable = true)
|-- item: string (nullable = true)
CodePudding user response:
I am going to solve this with Spark SQL instead of dataframes. Both solutions work. However, this has an important enhancement.
#
# 1 - create data file
#
# raw data
json_str = """
{"customer": 10, "date": "2017.04.06 12:09:32", "itemList": [{"item": "20126907_EA", "price": 1.88, "quantity": 1.0}, {"item": "20185742_EA", "price": 0.99, "quantity": 1.0}, {"item": "20138681_EA", "price": 1.79, "quantity": 1.0}, {"item": "20049778001_EA", "price": 2.47, "quantity": 1.0}, {"item": "20419715007_EA", "price": 3.33, "quantity": 1.0}, {"item": "20321434_EA", "price": 2.47, "quantity": 1.0}, {"item": "20068076_KG", "price": 28.24, "quantity": 10.086}, {"item": "20022893002_EA", "price": 1.77, "quantity": 1.0}, {"item": "20299328003_EA", "price": 1.25, "quantity": 1.0}], "store": "825f9cd5f0390bc77c1fed3c94885c87"}
"""
# raw file
dbutils.fs.put("/temp/transactions.json", json_str, True)
The above code writes a temporary file.
#
# 2 - read data file w/schema
#
# use library
from pyspark.sql.types import *
# define schema
schema = StructType([
StructField("customer", StringType(), True),
StructField("date", StringType(), True),
StructField("itemList",
ArrayType(
StructType([
StructField("item", StringType(), True),
StructField("price", DoubleType(), True),
StructField("quantity", DoubleType(), True)
])
), True),
StructField("store", StringType(), True)
])
# read in the data
df1 = spark \
.read \
.schema(schema) \
.option("multiline", "true") \
.json("/temp/transactions.json")
# make temp hive view
df1.createOrReplaceTempView("transaction_data")
This is the most important part of the solution, always use a schema with a text file. You do not want the processing code guessing at the format. This will take considerable time if the file is large.
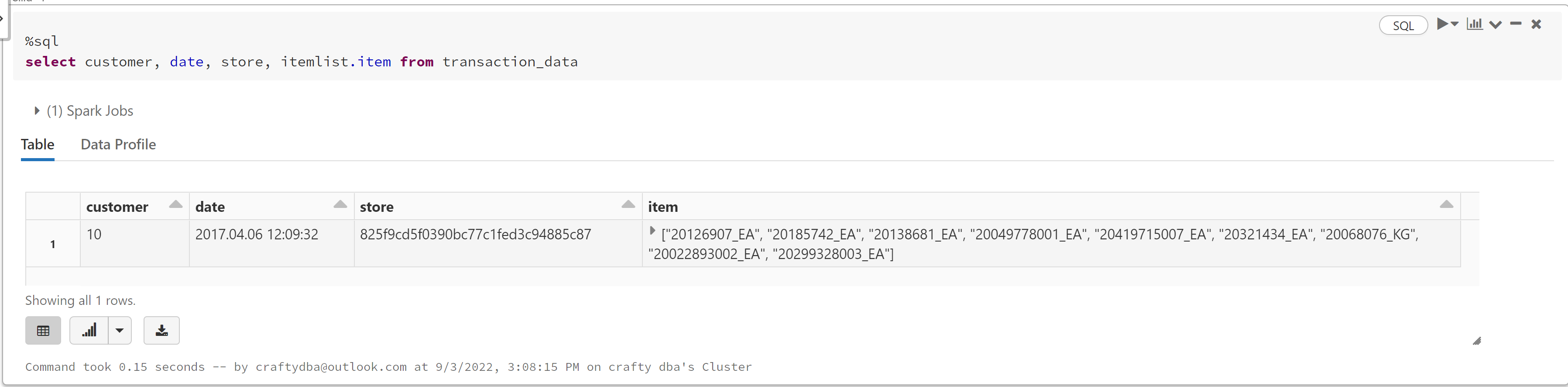
We can use the "%sql" magic command to execute a Spark SQL statement. Use the dot notation to reference an element within the array of structures.
If you want to have this data on each row, use the explode command.
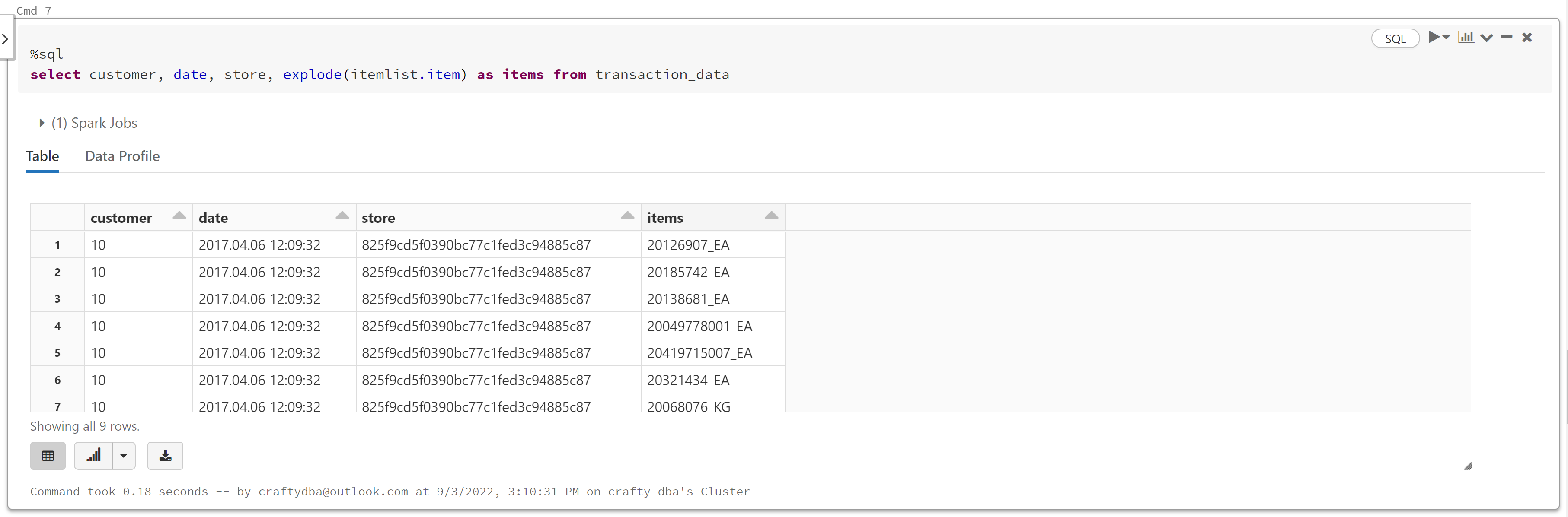
Now that we have the final format, we can write the data to disk (optional).
