I have a csv file with below data
Tran_id,Tran_date1,Tran_date2,Tran_date3
1,2022-07-02T16:53:30.375Z,2022-07-02T16:53:30.3750000 00:00,2022-07-02 16:53:30.3750000 00:00
2,2022-08-02T17:33:10.456Z,2022-08-02T17:33:10.4560000 00:00,2022-08-02 17:33:10.4560000 00:00
3,2022-09-02T18:13:20.375Z,2022-09-02T18:13:20.3750000 00:00,2022-09-02 18:13:20.3750000 00:00
4,2022-09-02T19:23:90.322Z,2022-09-02T19:23:90.3220000 00:00,2022-09-02 19:23:90.3220000 00:00
I want to read this csv file using pyspark and convert the data to below format
root
|-- Tran_id: integer (nullable = false)
|-- Tran_date1: TimestampType(nullable = false)
|-- Tran_date2: TimestampType(nullable = false)
|-- Tran_date3: TimestampType(nullable = false)
and save this data into hive table by converting the string type to timestamptype
how to convert the string into timestamptype without losing the format
CodePudding user response:
You could have read your csv file with automatic conversion to the required type, like this:
spark.read.option("header","true").option("inferSchema", "true").csv("test.csv")
df.printSchema()
root
|-- Tran_id: integer (nullable = true)
|-- Tran_date1: string (nullable = true)
|-- Tran_date2: string (nullable = true)
|-- Tran_date3: string (nullable = true)
But as you can see with your data it won't give you the correct schema. The reason is that you have some bad data in your csv. E.g. look at your record #4: 022-09-02T19:23:90.322Z, i.e. there can't be 90 seconds.
You can do the parsing yourself:
df = (
spark.read
.option("header","true")
.csv("test.csv")
.select(
"Tran_id",
F.to_timestamp("Tran_date1").alias("Tran_date1"),
F.to_timestamp("Tran_date2").alias("Tran_date2"),
F.to_timestamp("Tran_date3").alias("Tran_date3")))
# Schema is correct now
df.printSchema()
root
|-- Tran_id: string (nullable = true)
|-- Tran_date1: timestamp (nullable = true)
|-- Tran_date2: timestamp (nullable = true)
|-- Tran_date3: timestamp (nullable = true)
# But we now have nulls for bad data
df.show(truncate=False)
------- ----------------------- ----------------------- -----------------------
|Tran_id|Tran_date1 |Tran_date2 |Tran_date3 |
------- ----------------------- ----------------------- -----------------------
|1 |2022-07-02 16:53:30.375|2022-07-02 16:53:30.375|2022-07-02 16:53:30.375|
|2 |2022-08-02 17:33:10.456|2022-08-02 17:33:10.456|2022-08-02 17:33:10.456|
|3 |2022-09-02 18:13:20.375|2022-09-02 18:13:20.375|2022-09-02 18:13:20.375|
|4 |null |null |null |
------- ----------------------- ----------------------- -----------------------
With the correct schema in place, you can later save you dataframe to hive, spark will take care of preserving the types.
CodePudding user response:
I chose to show you have to solve this problem with Spark SQL.
#
# Create sample dataframe view
#
# array of tuples - data
dat1 = [
(1,"2022-07-02T16:53:30.375Z","2022-07-02T16:53:30.3750000 00:00","2022-07-02 16:53:30.3750000 00:00"),
(2,"2022-08-02T17:33:10.456Z","2022-08-02T17:33:10.4560000 00:00","2022-08-02 17:33:10.4560000 00:00"),
(3,"2022-09-02T18:13:20.375Z","2022-09-02T18:13:20.3750000 00:00","2022-09-02 18:13:20.3750000 00:00"),
(4,"2022-09-02T19:23:90.322Z","2022-09-02T19:23:90.3220000 00:00","2022-09-02 19:23:90.3220000 00:00")
]
# array of names - columns
col1 = ["Tran_id", "Tran_date1", "Tran_date2", "Tran_date3"]
# make data frame
df1 = spark.createDataFrame(data=dat1, schema=col1)
# make temp hive view
df1.createOrReplaceTempView("sample_data")
# show schema
df1.printSchema()
Instead of creating a file on my Azure Databrick's storage, I decided to use an array of tuples since this is a very simple file.
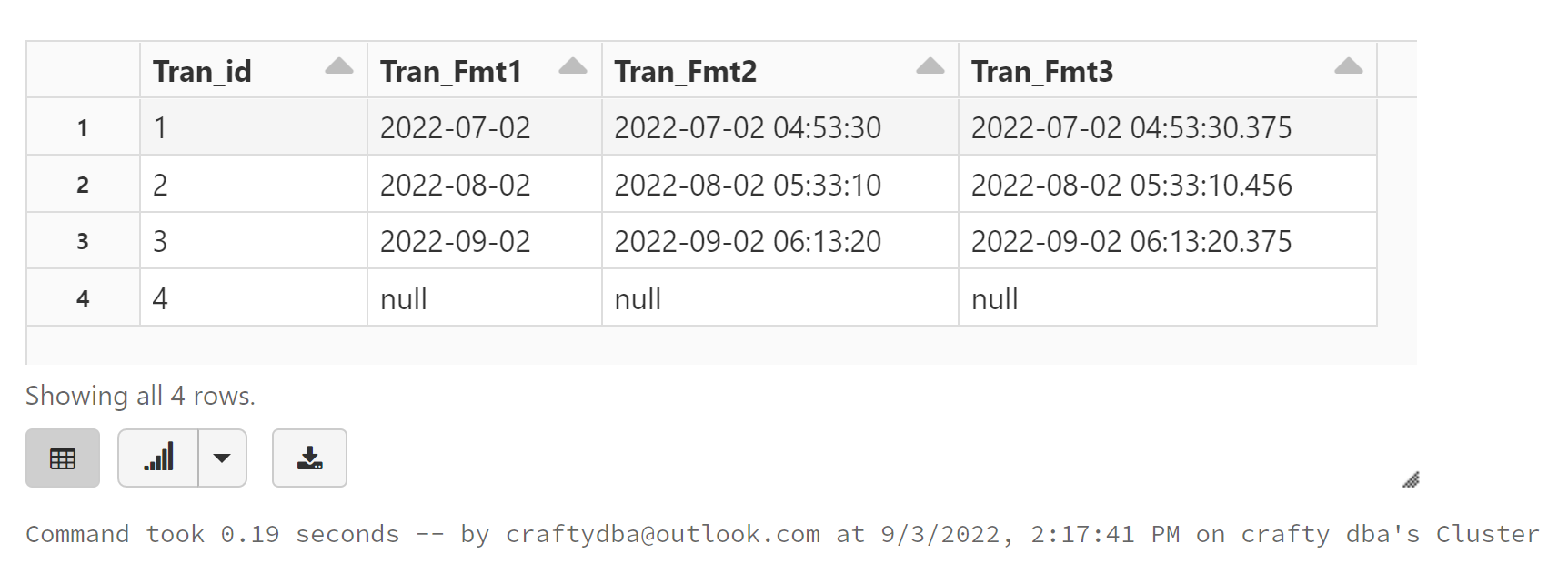
We can see from the image below that the last three fields are strings.

The code below uses spark functions to convert the information from string to timestamp.
See this link for Spark SQL functions.

I totally agree with qaziqarta.
Once the data is a timestamp, you can format it any which way you want either in the front end reporting tool (Power BI) or convert it to a formatted string in the curated zone as a file ready formatted for reporting.
See link for Spark SQL Function.

Here is execution and output of the above SQL to obtain formatted strings representing date, date/timestamp and date/extended timestamp.