I have a pyspark dataframe with sales dataset for 4 months where I need to calculate last 3 month sales average.
This is what it is supposed to look like. So for September for a given sales rep, L3M should be Sales of (June July August) / 3, if for a given rep there's no data entries for say July then it should just be (June August) / 2.
How can I best do this in pyspark?
CodePudding user response:
Not sure what's the best solution, but I've tried something like this:
from pyspark.sql import SparkSession
from pyspark.sql import functions as F
from pyspark.sql.window import Window
spark = SparkSession.builder.getOrCreate()
data = [
{"Date": "2022-06-03", "Month": "202206", "Sales": 50, "Store_ID": 555, "Sales_Rep": 211},
{"Date": "2022-06-19", "Month": "202206", "Sales": 10, "Store_ID": 555, "Sales_Rep": 211},
{"Date": "2022-06-27", "Month": "202206", "Sales": 60, "Store_ID": 555, "Sales_Rep": 211},
{"Date": "2022-07-02", "Month": "202207", "Sales": 0, "Store_ID": 555, "Sales_Rep": 211},
{"Date": "2022-08-05", "Month": "202208", "Sales": 30, "Store_ID": 555, "Sales_Rep": 211},
{"Date": "2022-08-09", "Month": "202208", "Sales": 10, "Store_ID": 555, "Sales_Rep": 211},
{"Date": "2022-09-03", "Month": "202209", "Sales": 70, "Store_ID": 555, "Sales_Rep": 211},
{"Date": "2022-09-07", "Month": "202209", "Sales": 20, "Store_ID": 555, "Sales_Rep": 211},
]
month_window = Window.partitionBy(["Store_ID"]).orderBy("Month_tmp").rangeBetween(-3, -1)
df = spark.createDataFrame(data=data)
df_grouped = df.groupBy(["Store_ID", "Month"]).agg(F.sum("Sales").alias("average"))
df_grouped = df_grouped.withColumn("Month_tmp", F.month(F.to_date("Month", "yyyyMM")))
df_grouped = df_grouped.withColumn("tmp", F.count("average").over(month_window))
df_grouped = df_grouped.withColumn("L3M", F.round(F.sum("average").over(month_window) / F.col("tmp"), 2))
df = (
df.alias("df")
.join(df_grouped.alias("df2"), df.Month == df_grouped.Month)
.select("df.Date", "df.Month", "df.Sales", "df.Sales_Rep", "df.Store_ID", "df2.L3M")
)
df.show(10, False)
df.printSchema()
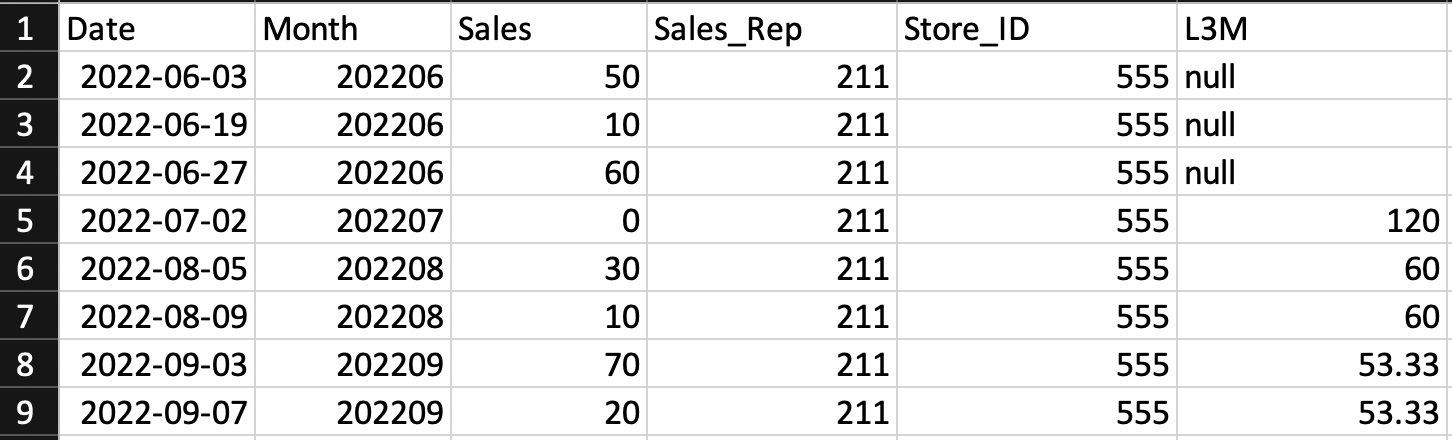
Which gives:
---------- ------ ----- --------- -------- -----
|Date |Month |Sales|Sales_Rep|Store_ID|L3M |
---------- ------ ----- --------- -------- -----
|2022-06-03|202206|50 |211 |555 |null |
|2022-06-19|202206|10 |211 |555 |null |
|2022-06-27|202206|60 |211 |555 |null |
|2022-07-02|202207|0 |211 |555 |120.0|
|2022-08-05|202208|30 |211 |555 |60.0 |
|2022-08-09|202208|10 |211 |555 |60.0 |
|2022-09-03|202209|70 |211 |555 |53.33|
|2022-09-07|202209|20 |211 |555 |53.33|
---------- ------ ----- --------- -------- -----
root
|-- Date: string (nullable = true)
|-- Month: string (nullable = true)
|-- Sales: long (nullable = true)
|-- Sales_Rep: long (nullable = true)
|-- Store_ID: long (nullable = true)
|-- L3M: double (nullable = true)
I'm also not sure how well will this perform on the full data, but it gives you an example of how to use groupBy, rangeBetween, and Window to isolate the data you need.