Can someone help me write query that shows data as follows: column AMOUNT has pairs of duplicates and column CASH_CO has differnt values on each pair.
I tired this but it shows no results. I check DB manually and there are such items.
SELECT S1.AMOUNT, S1.CASH_CO, S1.ACCOUNT_ID
FROM HI_MTI_O1 S1
INNER JOIN HI_MTI_01 S2
ON (S1.ACCOUNT_ID = S2.ACCOUNT_ID AND S1.AMOUNT = S2.CASH_CO)
WHERE (S1.CASH_CO <> S1.CASH_CO AND S1.AMOUNT = S2.AMOUNT)
FETCH FIRST 100 ROWS ONLY;
CodePudding user response:
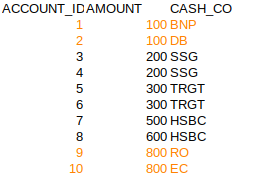
WITH HI_MTI_O1 (ACCOUNT_ID, AMOUNT, CASH_CO) AS
(
VALUES
( 1, 100, 'BNP')
, ( 2, 100, 'DB')
, ( 3, 200, 'SSG')
, ( 4, 200, 'SSG')
, ( 5, 300, 'TRGT')
, ( 6, 300, 'TRGT')
, ( 7, 500, 'HSBC')
, ( 8, 600, 'HSBC')
, ( 9, 800, 'RO')
, (10, 800, 'EC')
)
SELECT S.*
FROM HI_MTI_O1 S
JOIN
(
SELECT AMOUNT
FROM HI_MTI_O1
GROUP BY AMOUNT
HAVING COUNT (DISTINCT CASH_CO) > 1
) G ON G.AMOUNT = S.AMOUNT
ORDER BY S.ACCOUNT_ID
| ACCOUNT_ID | AMOUNT | CASH_CO |
|---|---|---|
| 1 | 100 | BNP |
| 2 | 100 | DB |
| 9 | 800 | RO |
| 10 | 800 | EC |