df = data.frame(record = c(20200525,20200608,20200608,20200615,20200615,20200622,20200622,20200701,20200701,20200706,20200706,20200713,20200713,20200727,20200727,20200803), team = c("A","A","B","B","C","C","D","D","E","E","F","F","G","G","H","H"))
Want to use df$record min as value of column S, max as value of column E in each team. and would be looking for an answer like this:
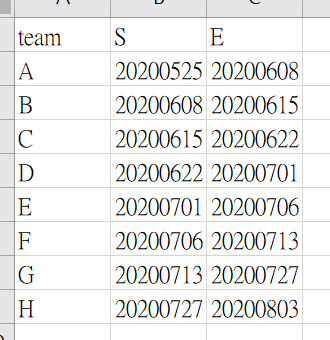
I tried using:
df %>% mutate(S = top_n(1, record) ,E = top_n(-1, record))
and it gave me Error... Thanks for any help.
CodePudding user response:
Here is a solution. Group by team and then summarise the data.
df = data.frame(record = c(20200525,20200608,20200608,20200615,20200615,
20200622,20200622,20200701,20200701,20200706,
20200706,20200713,20200713,20200727,20200727,
20200803),
team = c("A","A","B","B","C","C","D","D","E",
"E","F","F","G","G","H","H"))
suppressPackageStartupMessages(library(dplyr))
df %>%
group_by(team) %>%
summarise(S = min(record), E = max(record))
#> # A tibble: 8 × 3
#> team S E
#> <chr> <dbl> <dbl>
#> 1 A 20200525 20200608
#> 2 B 20200608 20200615
#> 3 C 20200615 20200622
#> 4 D 20200622 20200701
#> 5 E 20200701 20200706
#> 6 F 20200706 20200713
#> 7 G 20200713 20200727
#> 8 H 20200727 20200803
Created on 2022-09-11 by the reprex package (v2.0.1)