I have a bit of a predicament with some bad data in Postgres. I have three tables, e.g., family, genus, and audit_log_event. A family can have many genuses, and genus has a foreign key reference to family.id.
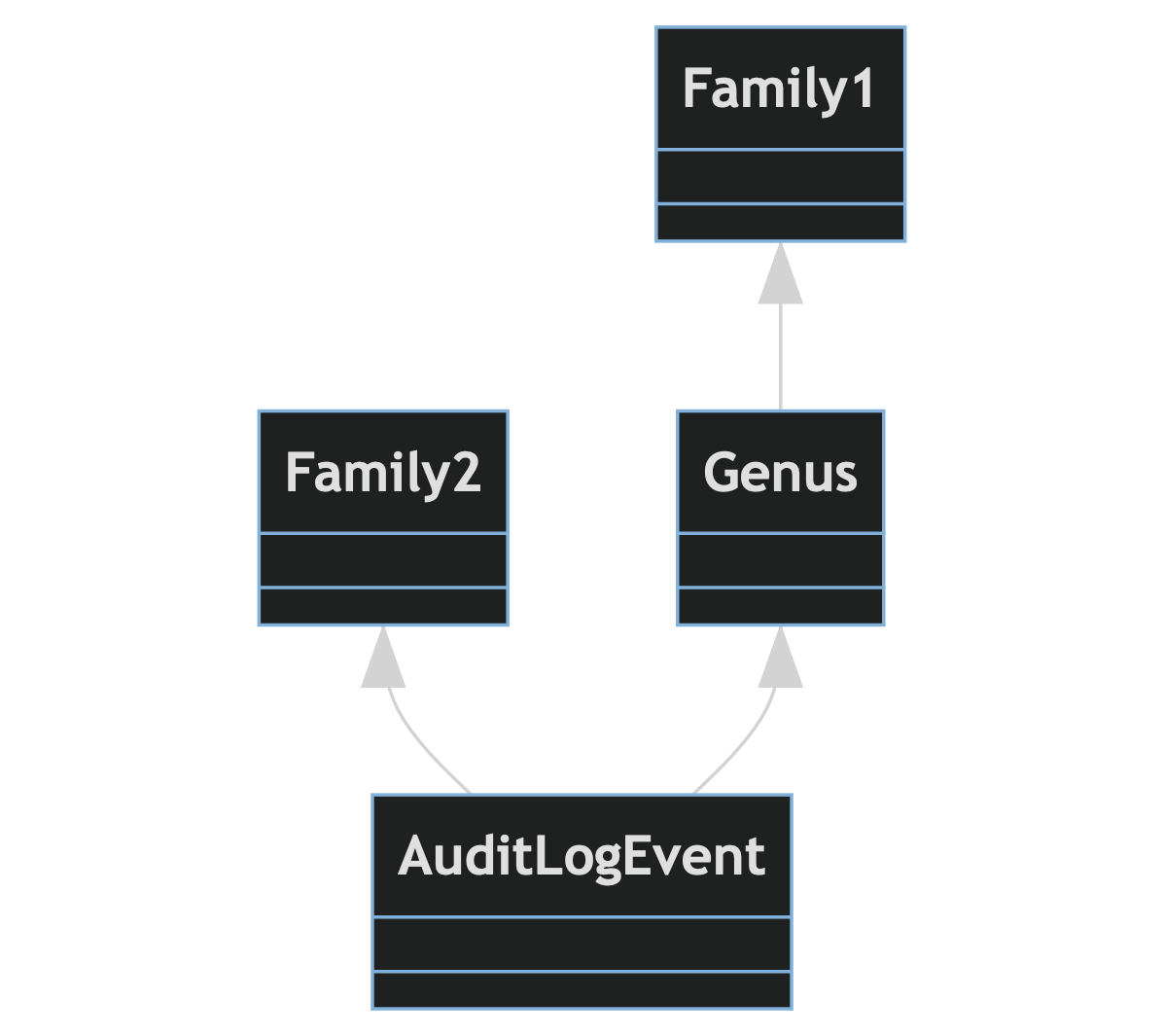
audit_log_event has two foreign key columns: family_id and genus_id. Due to some buggy code making it to production, I now have audit_log_events that reference a genus_id and family_id, but the genus referenced by genus_id references a different family than what is referenced by family_id on the same audit_log_event.
Put visually, I have data that looks like this:
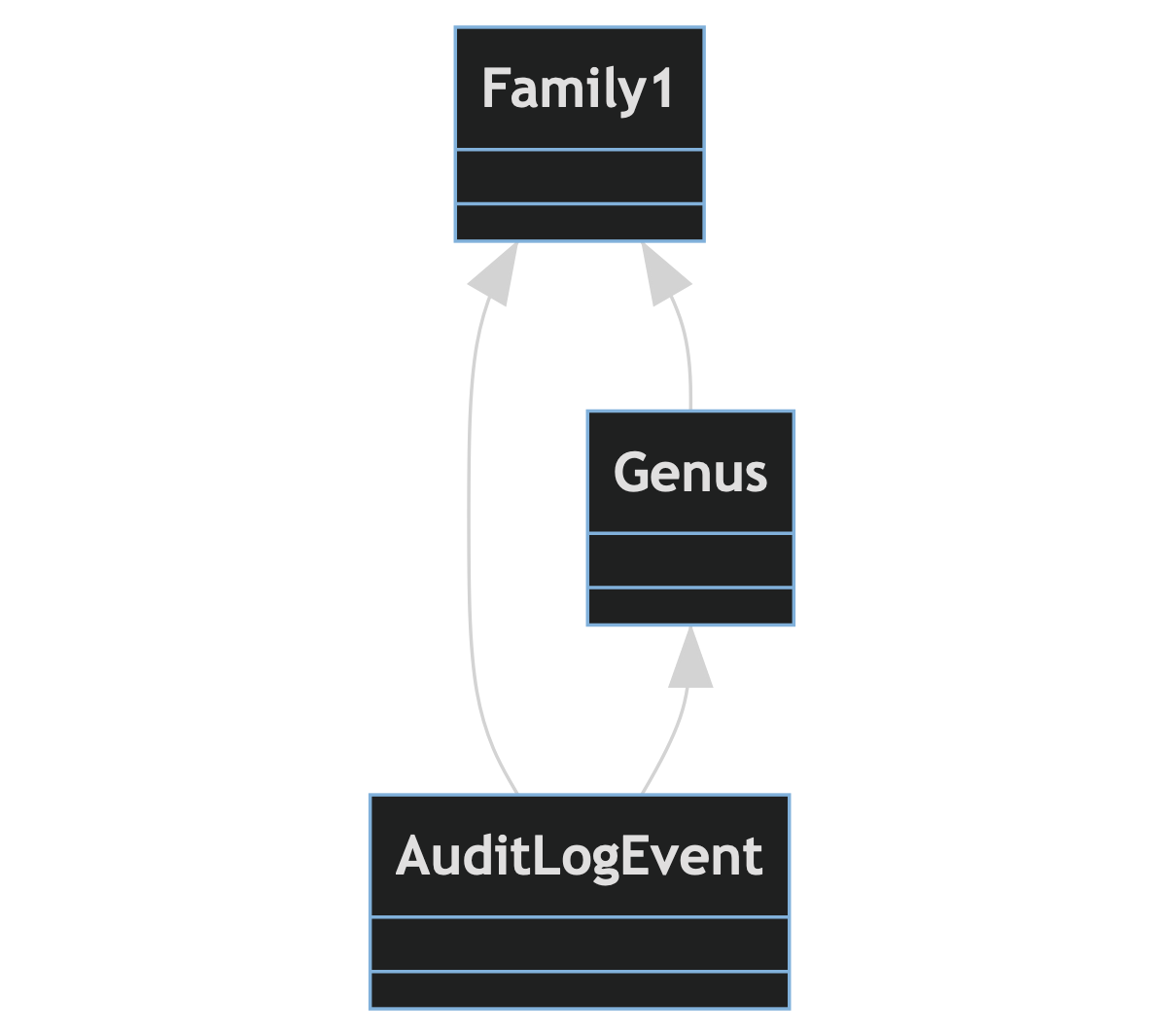
I want to update the existing audit_log_events to reference the family referenced by the genus referenced by each audit_log_event:
How can I select the audit_log_events that reference different familys than their referenced genuses reference? Is there any way to perform an UPDATE query to let Postgres handle fixing the data, or would it be better to just select all the bad data and update it programatically outside of the database engine?
I tried the following SQL query:
SELECT
a.genus_id as a_genus_id,
a.family_id as a_family_id,
a.id as audit_log_event_id
FROM genus g
JOIN audit_log_events a
ON g.family_id = a.family_id AND a.genus_id != g.id
But this actually selects valid data and I'm having a hard time wrapping my head around making a join select invalid data.
CodePudding user response:
Do not trust random query you found online outright, please test properly and evaluate
You can do an update on a column with value taken from a select with limit 1 on a single column as such:
update audit_log_event as al
set family_id = (select family_id from genus as g
where g.id = al.genus_id limit 1);
The query above will update every rows to use the family_id referred by the genus_id. Hope it helps.
Also, normalizing the table would be very helpful in maintainability in the long run - though some may argue performance is worse or something.
See fiddle: https://www.db-fiddle.com/f/sddj65SkSvHjVoNsGjr5Jq/0
EDIT:
The following query should give you a preview of the records which will be affected:
SELECT
id,
family_id,
genus_id
FROM
audit_log_event AS al
WHERE
family_id != (
SELECT
family_id
FROM
genus AS g
WHERE
g.id = a.genus_id)