Consider the following two dataframes:
Dataframe1 contains a list of users and stop_dates
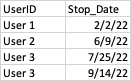
Dataframe2 contains a history of user transactions and dates
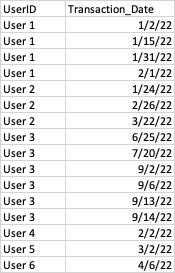
I want to get the last transaction date before the stop date for all users in Dataframe1 (some users in Dataframe1 have multiple stop dates)
I want the output to look like the following:
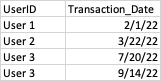
CodePudding user response:
Here is one way to accomplish (make sure both date columns are already datetime):
df = pd.merge(df1, df2, on="UserID")
df["Last_Before_Stop"] = df["Stop_Date"].apply(lambda x: max(df["Transaction_Date"][df["Transaction_Date"] <= x]))
CodePudding user response:
Please always provide data in a form that makes it easy to use as samples (i.e. as text, not as images - see here).
You could try:
df1["Stop_Date"] = pd.to_datetime(df1["Stop_Date"], format="%m/%d/%y")
df2["Transaction_Date"] = pd.to_datetime(df2["Transaction_Date"], format="%m/%d/%y")
df = (
df1.merge(df2, on="UserID", how="left")
.loc[lambda df: df["Stop_Date"] >= df["Transaction_Date"]]
.groupby(["UserID", "Stop_Date"])["Transaction_Date"].max()
.to_frame().reset_index().drop(columns="Stop_Date")
)
- Make
datetimes out of the date columns. - Merge
df2ondf1alongUserID. - Remove the rows which have a
Transaction_Dategreater thanStop_Date. - Group the result by
UserIDandStop_Date,and fetch the maximumTransaction_Date. - Bring the result in shape.
Result for
df1:
UserID Stop_Date
0 1 2/2/22
1 2 6/9/22
2 3 7/25/22
3 3 9/14/22
df2:
UserID Transaction_Date
0 1 1/2/22
1 1 2/1/22
2 1 2/3/22
3 2 1/24/22
4 2 3/22/22
5 3 6/25/22
6 3 7/20/22
7 3 9/13/22
8 3 9/14/22
9 4 2/2/22
is
UserID Transaction_Date
0 1 2022-02-01
1 2 2022-03-22
2 3 2022-07-20
3 3 2022-09-14
If you don't want to permanently change the dtype to datetime, and also want the result as string, similarly formatted as the input (with padding), then you could try:
df = (
df1
.assign(Stop_Date=pd.to_datetime(df1["Stop_Date"], format="%m/%d/%y"))
.merge(
df2.assign(Transaction_Date=pd.to_datetime(df2["Transaction_Date"], format="%m/%d/%y")),
on="UserID", how="left"
)
.loc[lambda df: df["Stop_Date"] >= df["Transaction_Date"]]
.groupby(["UserID", "Stop_Date"])["Transaction_Date"].max()
.to_frame().reset_index().drop(columns="Stop_Date")
.assign(Transaction_Date=lambda df: df["Transaction_Date"].dt.strftime("%m/%d/%y"))
)
Result:
UserID Transaction_Date
0 1 02/01/22
1 2 03/22/22
2 3 07/20/22
3 3 09/14/22