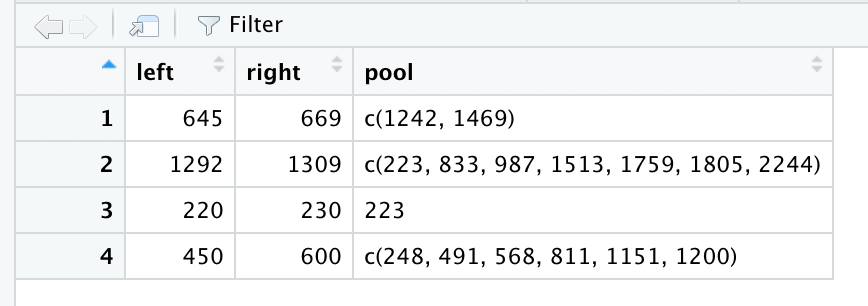
I'm working with a data frame where each row contains 3 columns: a left bound, right bound and a list of values "pool".
test <- structure(list(left = c(645, 1292, 220, 450), right = c(669,
1309, 230, 600), pool = list(structure(c(1242L, 1469L), match.length = c(6L,
6L), index.type = "chars", useBytes = TRUE), structure(c(223L,
833L, 987L, 1513L, 1759L, 1805L, 2244L), match.length = c(6L,
6L, 6L, 6L, 6L, 6L, 6L), index.type = "chars", useBytes = TRUE),
structure(223L, match.length = 6L, index.type = "chars", useBytes = TRUE),
structure(c(248L, 491L, 568L, 811L, 1151L, 1200L), match.length = c(6L,
6L, 6L, 6L, 6L, 6L), index.type = "chars", useBytes = TRUE))), row.names = c(NA,
-4L), class = c("tbl_df", "tbl", "data.frame"))
What I'm trying to accomplish is
- for each row, are any of the values in the pool between the left and right bounds? This should return a vector of FALSE FALSE TRUE TRUE
- which element(s) of the list are between the bounds? Should return NA NA 223 (491,568)
I'm getting close using lapply and specifying the index of each row individually.
> lapply(test$pool[1], between, left = test$left[1], right = test$right[1])
[[1]]
[1] FALSE FALSE
> lapply(test$pool[2], between, left = test$left[2], right = test$right[2])
[[1]]
[1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE
> lapply(test$pool[3], between, left = test$left[3], right = test$right[3])
[[1]]
[1] TRUE
> lapply(test$pool[4], between, left = test$left[4], right = test$right[4])
[[1]]
[1] FALSE TRUE TRUE FALSE FALSE FALSE
But I'm not good enough with lists yet to get my head around how to apply this over all the rows of the dataframe for part 1, or to extract out the list entries for part 2.
Thanks for your expertise!
CodePudding user response:
You can use create a small function that checks if there are values between left and right, and returns those values (if any), and apply that function rowwise:
f <- function(l,r,p) {
bvals = between(p,l,r)
list(hasvals=any(bvals),vals=p[bvals])
}
test %>%
rowwise %>%
mutate(r = list(f(left,right, pool))) %>%
unnest_wider(r)
Output:
left right pool hasvals vals
<dbl> <dbl> <list> <lgl> <list>
1 645 669 <int [2]> FALSE <NULL>
2 1292 1309 <int [7]> FALSE <NULL>
3 220 230 <int [1]> TRUE <int [1]>
4 450 600 <int [6]> TRUE <int [2]>
CodePudding user response:
We can use rowwise, create a temporary column with a logical index for every element of pool values, use this index to create the logical between_any and integer values columns, then finally remove the index column.
library(dplyr)
test %>% rowwise() %>%
mutate(between = list(between(pool, left, right)),
between_any = any(between),
values = list(pool[between])) %>%
select(-between) %>%
ungroup()
# A tibble: 4 × 5
left right pool between_any values
<dbl> <dbl> <list> <lgl> <list>
1 645 669 <int [2]> FALSE <int [0]>
2 1292 1309 <int [7]> FALSE <int [0]>
3 220 230 <int [1]> TRUE <int [1]>
4 450 600 <int [6]> TRUE <int [2]>