I'm trying to understand how to leverage cache() to improve my performance. Since cache retains a DataFrame in memory "for reuse", it seems like i need to understand the conditions that eject the DataFrame from memory to better understand how to leverage it.
After defining transformations, I call an action, is the dataframe, after the action completes, gone from memory? This would imply that if I do execute an action on a dataframe, but I continue to do other stuff with the data, all the previous parts of the DAG, from the read to the action, will need to be re done.
Is this accurate?
CodePudding user response:
Quote...
Using cache() and persist() methods, Spark provides an optimization mechanism to store the intermediate computation of a Spark DataFrame so they can be reused in subsequent actions.
See 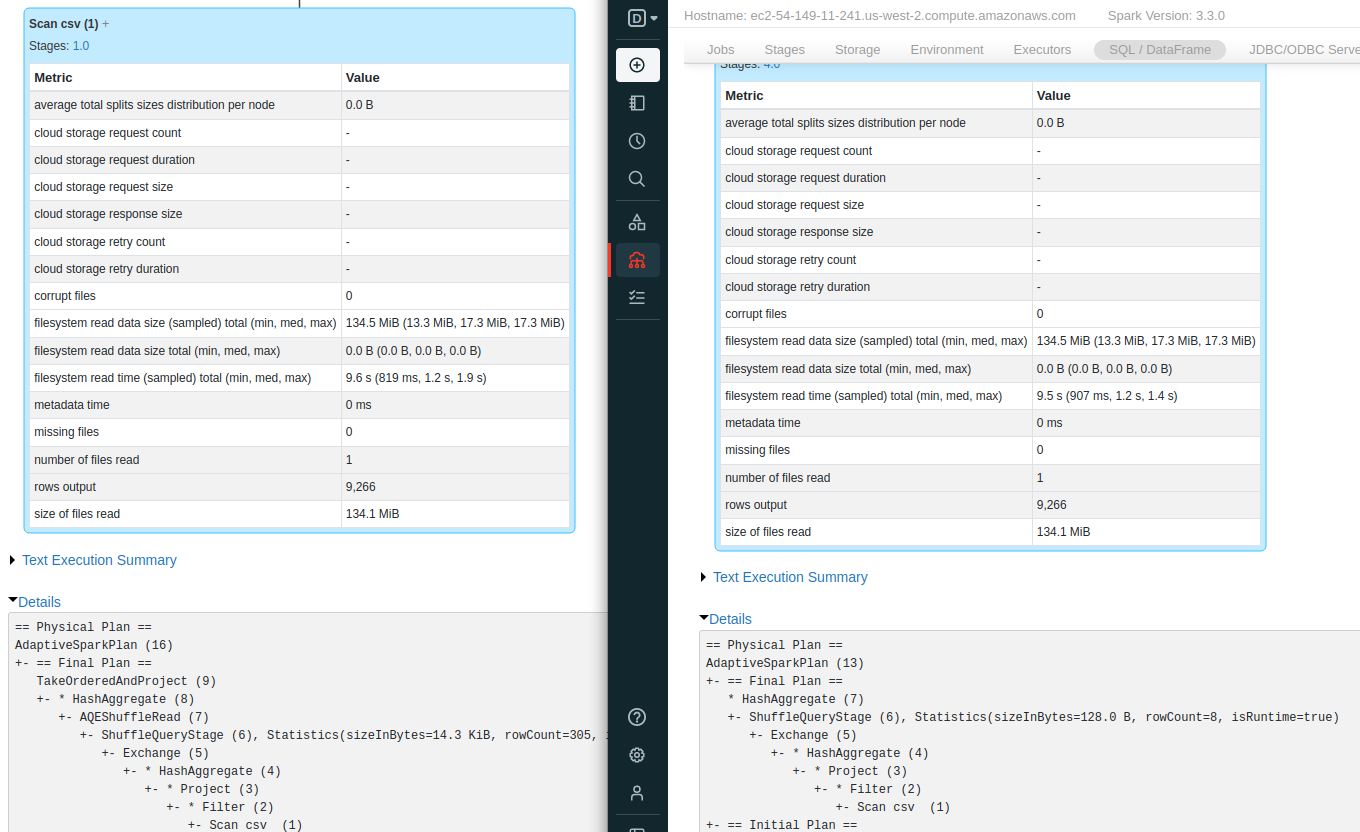
If you cache intermediate results after first .filter(col("City") === "Warsaw") and then use this cached DF to do grouping and count you will still find two separate dags (number of action has not changed) but this time in the plan for second dag you will find "In memory table scan" instead of read of a csv file - that means that Spark is reading data from cache
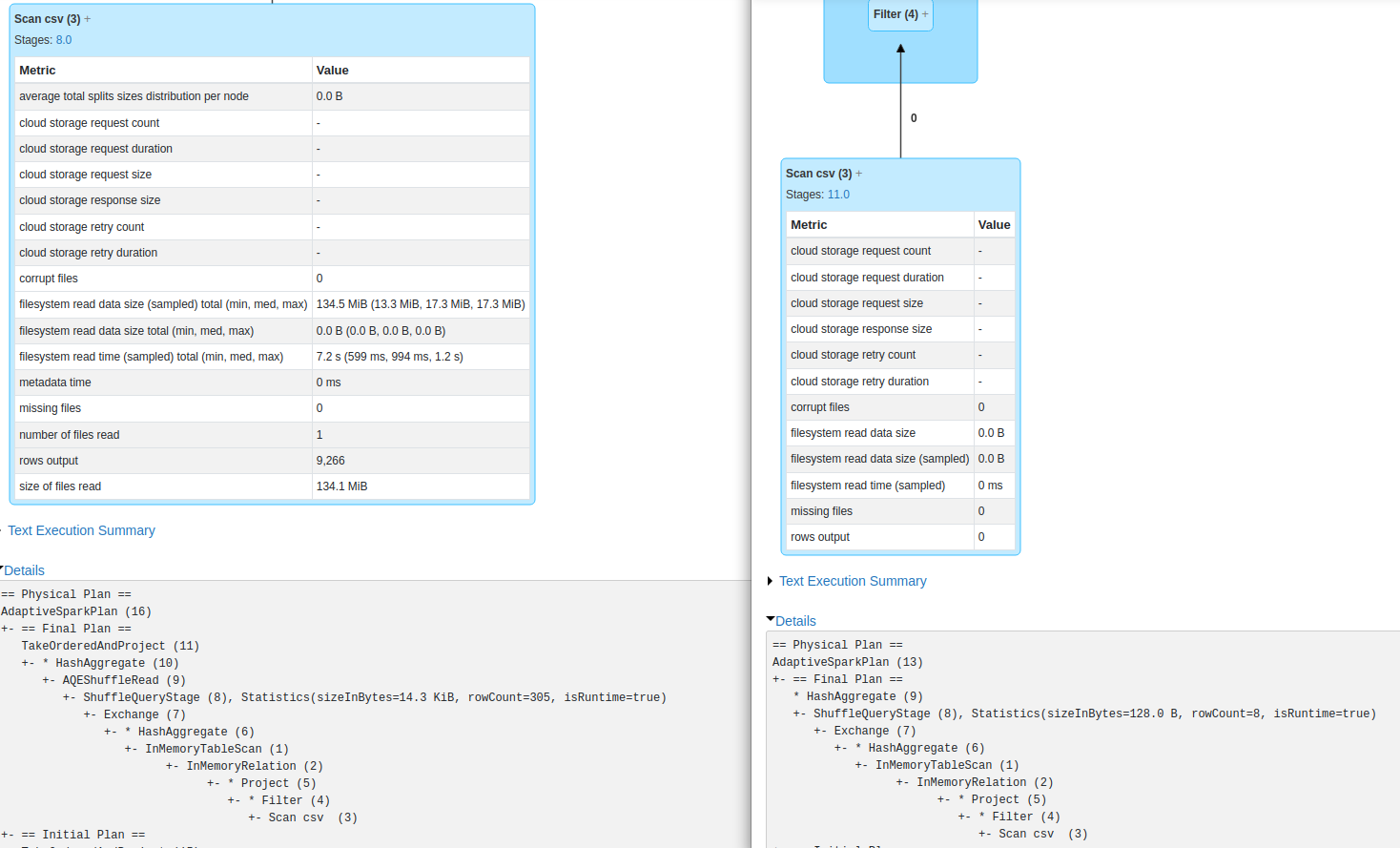
Now you can see in memory relation in plan. There is still read csv node in the dag but as you can see, for second action its skipped (0 bytes read)
** I am using Databrics cluster with Spark 3.2, SparkUI may look different on your env