There are two columns:
| col_A | col_B |
|---|---|
| 111 | 2.0 |
| 222 | 1.0 |
| 222 | 2.0 |
| 333 | 1.0 |
Using alter row transformation i would like to select rows that have repeated entries in col_A, in this example 222 and select the corresponding highest value in col_B i.e. 2.0
The output should look as follows:
| col_A | col_B |
|---|---|
| 111 | 2.0 |
| 222 | 2.0 |
| 333 | 1.0 |
CodePudding user response:
You can use Aggregate transformation in Data flow.
This is my source data:
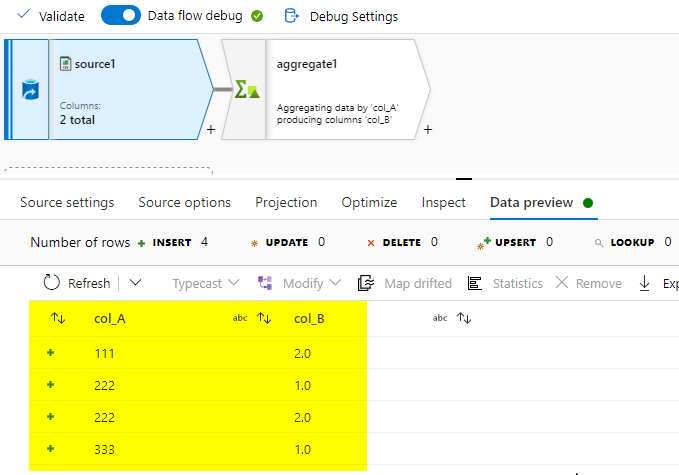
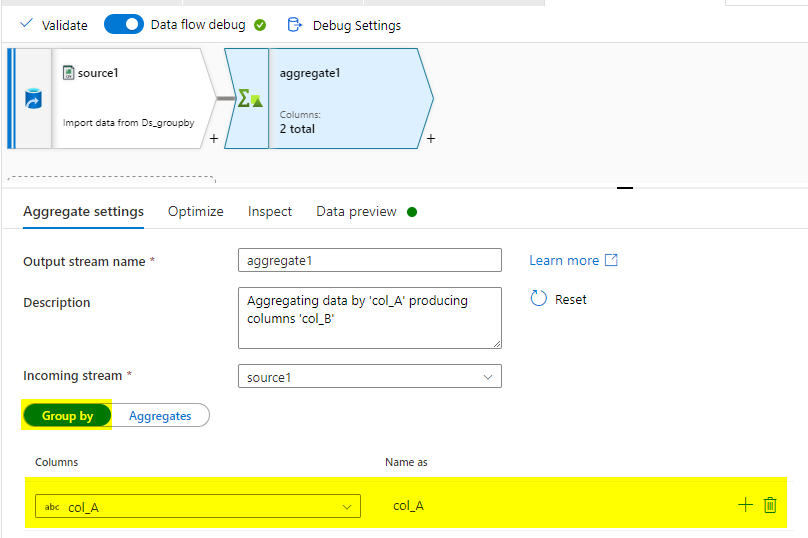
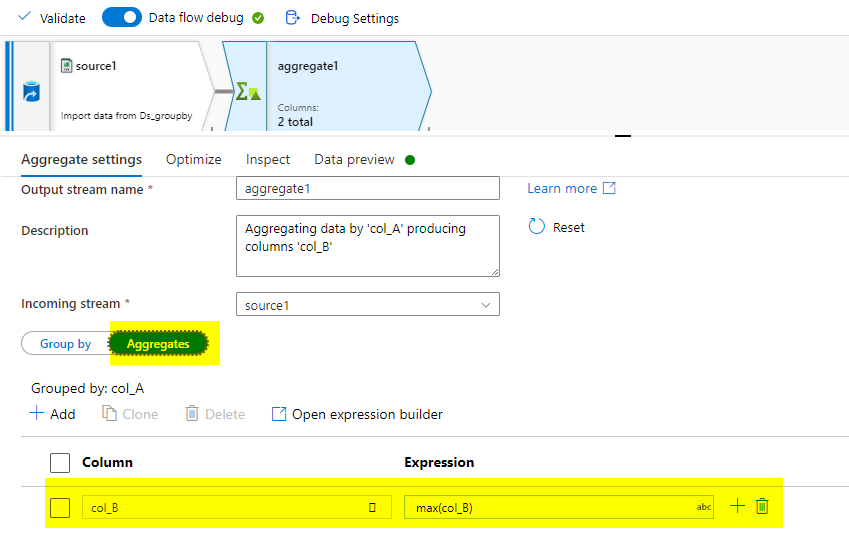
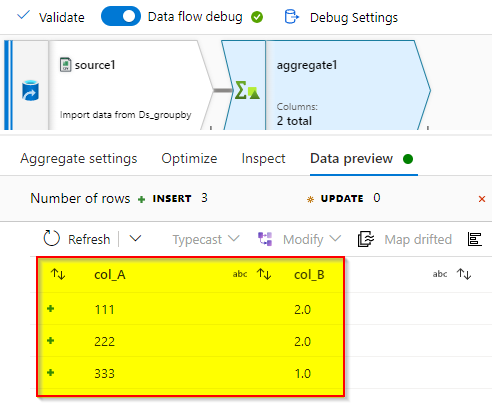
In the Aggregate transformation, give col_A for group by to select the distict rows and col_B for aggregate. Use the max(col_B) in this to get the max values.
Group By:
Aggregate:
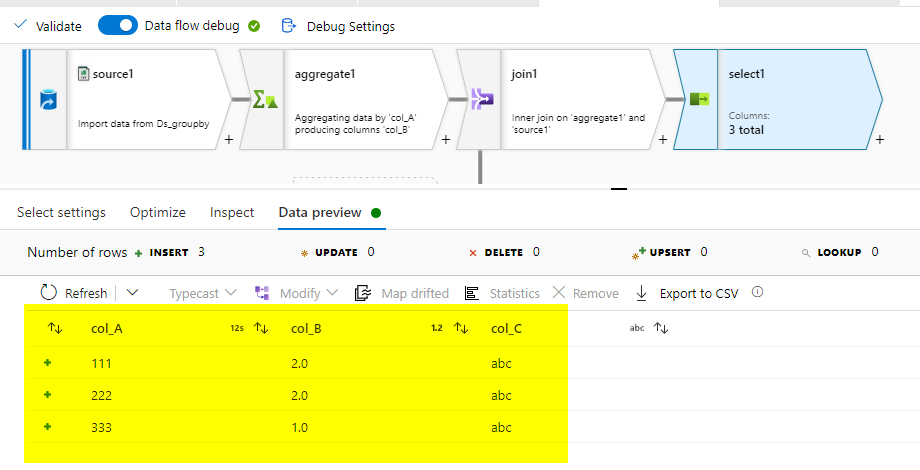
Result:
Update about Extra Columns:
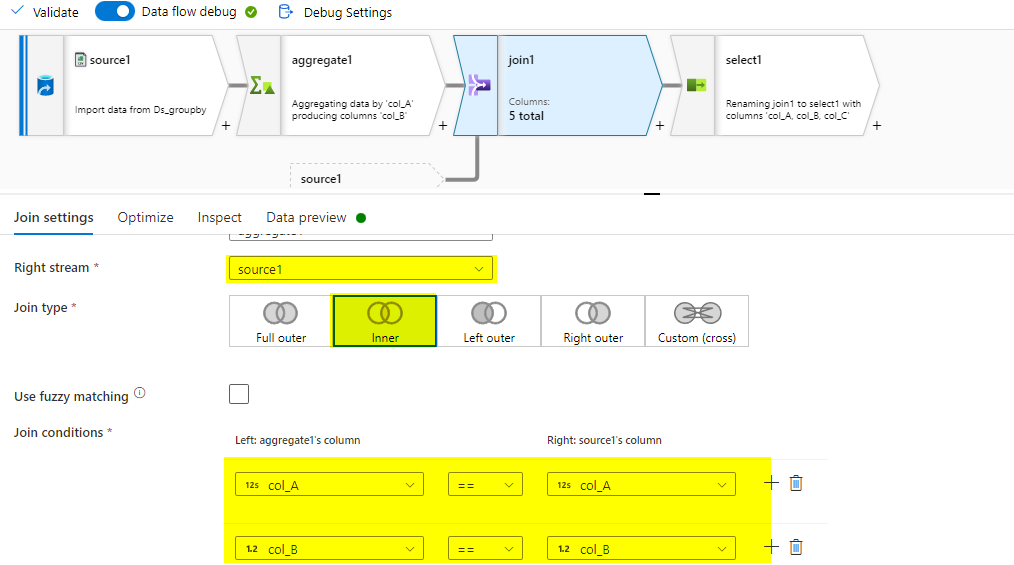
To Carry the Remaining columns after aggregation transformation, use Join transformation with Join type as inner join(Join of above with source) and give the above two columns as Keys.
After Join, you can remove the extra columns with select transformation.
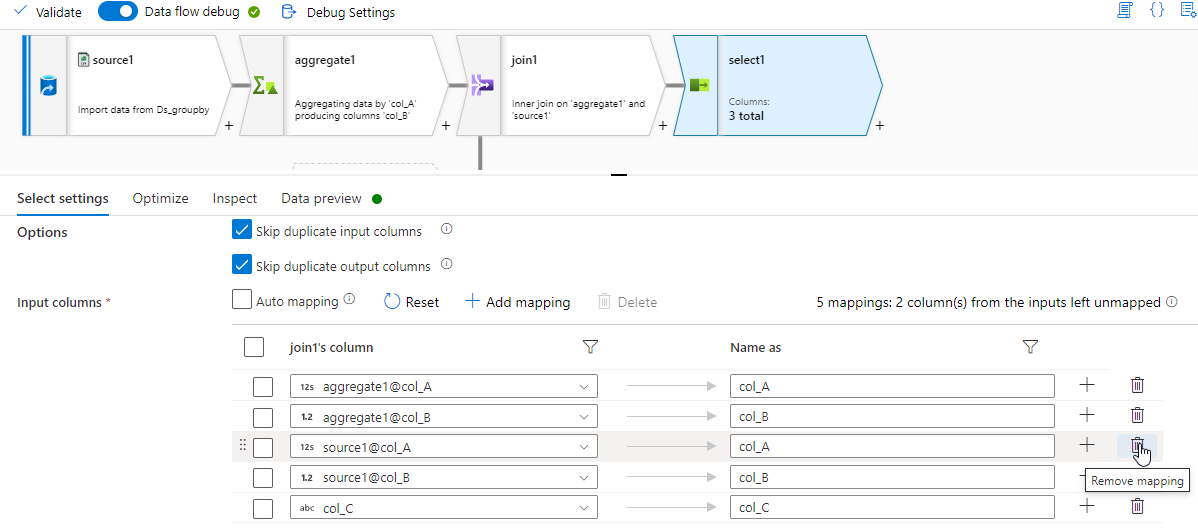
Result with Extra rows: