I am trying to generate data with some probability. Below you can see one example:
import numpy as np
import pandas as pd
df_categories = pd.DataFrame(np.random.choice(a=["M", "F"], size=100, p=[0.7, 0.3]),
columns = ['gender'])
df_categories
df_categories['gender'].value_counts()
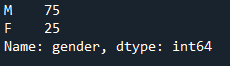
So far so good. Now I want to repeat this but with following categories: "TypeOfIncome_1","TypeOfIncome_2","TypeOfIncome_3","TypeOfIncome_4","TypeOfIncome_5","TypeOfIncome_6","TypeOfIncome_7","TypeOfIncome_8"
Each of these categories have some specific probability [0.6,0.2,0.05,0.03,0.03,0.03,0.03,0.03] or in total 1.
Similar to the example above I want to create a table with these probabilities
df_categories = pd.DataFrame(np.random.choice(["TypeOfIncome_1","TypeOfIncome_2","TypeOfIncome_3","TypeOfIncome_4","TypeOfIncome_5","TypeOfIncome_6","TypeOfIncome_7","TypeOfIncome_8"], 100, [0.6,0.2,0.05,0.03,0.03,0.03,0.03,0.03])
, columns = ['source_of_income'])
df_categories
df_categories['source_of_income'].value_counts()
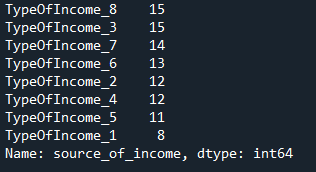
This example shows that TypeOfIncome_1, instead to have the largest frequency in the data frame, this variable has the smallest and so on. So can anybody help me how to create data with this probability [0.6,0.2,0.05,0.03,0.03,0.03,0.03,0.03] ?
CodePudding user response:
I would do it in this way:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
#---- set the population parameters
Ntrials = 10 # for testing
Ntrials = 1000000 # for production
p0 = [0.6, 0.2, 0.05, 0.03, 0.03, 0.03, 0.03, 0.03]
Nrange = len(p0)
#---- generate and evaluate the population
trials = np.random.choice(Nrange, Ntrials, p=p0)
histo = plt.hist(trials, bins=Nrange)
abs_histo = histo[0]
bins_bounds = histo[1]
print("abs_histo ", abs_histo);print()
print("bins_bounds", bins_bounds);print()
plt.show()
#---- generate the name list
name_list = np.array(["TypeOfIncome_" str(i 1) for i in range(Nrange)])
print("name_list", name_list);print()
#---- generate pandas data frame
df = pd.DataFrame({'Income_distribution':abs_histo }, index=name_list)
df
this gives
abs_histo [599502. 200493. 50267. 29829. 30020. 29924. 30001. 29964.]
bins_bounds [0. 0.875 1.75 2.625 3.5 4.375 5.25 6.125 7. ]
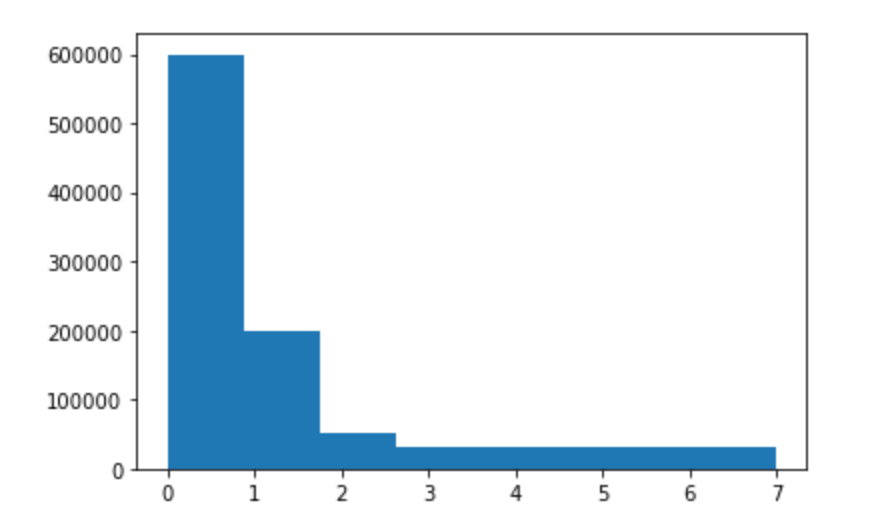
Income_distribution
TypeOfIncome_1 599502.0
TypeOfIncome_2 200493.0
TypeOfIncome_3 50267.0
TypeOfIncome_4 29829.0
TypeOfIncome_5 30020.0
TypeOfIncome_6 29924.0
TypeOfIncome_7 30001.0
TypeOfIncome_8 29964.0