Input:
import pandas as pd
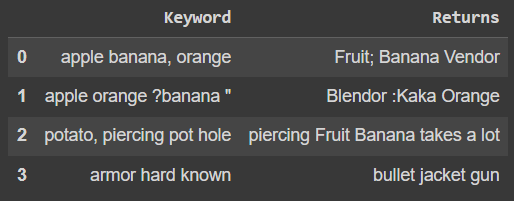
df_input = pd.DataFrame({'Keyword': {0: 'apple banana, orange',
1: 'apple orange ?banana "',
2: 'potato, piercing pot hole',
3: 'armor hard known'},
'Returns': {0: 'Fruit; Banana Vendor',
1: 'Blendor :Kaka Orange',
2: 'piercing Fruit Banana takes a lot',
3: 'bullet jacket gun'}})
df_input
For every word in Keyword column,
- if any of it appears in Returns column, Score = 1
- if none of it appears in Returns column, Score = 0
- if any of it appears in first half of the words in Returns column, Score_before = 1
- if any of it appears in second half of the words in Returns column, Score_after = 1
Output:
import pandas as pd
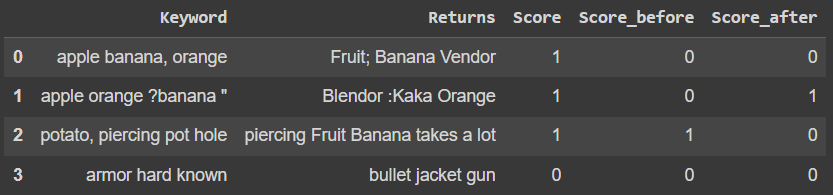
df_output = pd.DataFrame({'Keyword': {0: 'apple banana, orange',
1: 'apple orange ?banana "',
2: 'potato, piercing pot hole',
3: 'armor hard known'},
'Returns': {0: 'Fruit; Banana Vendor',
1: 'Blendor :Kaka Orange',
2: 'piercing Fruit Banana takes a lot',
3: 'bullet jacket gun'},
'Score': {0: 1, 1: 1, 2: 1, 3: 0},
'Score_before': {0: 0, 1: 0, 2: 1, 3: 0},
'Score_after': {0: 0, 1: 1, 2: 0, 3: 0}})
df_output
Original data frame has a million rows, how do I even tokenize the words efficiently? Should I use string operations instead?
(I've used from nltk.tokenize import word_tokenize before, but how to apply it on the whole data frame if that's the way?)
Edit: My custom function for tokenization:
import nltk
from nltk.tokenize import word_tokenize
nltk.download('punkt')
import string
def tokenize(s):
translator = str.maketrans('', '', string.punctuation)
s = s.translate(translator)
s = word_tokenize(s)
return s
tokenize('Finity: Stocks%, Direct$ MF, ETF')
CodePudding user response:
As you have as many conditions as you have rows, you need to loop here.
You can use a custom function:
import re
def get_scores(s1, s2):
words1 = set(re.findall('\w ', s1.casefold()))
words2 = re.findall('\w ', s2.casefold())
n = len(words2)//2
half1 = words2[:n]
half2 = words2[n:]
score_before = any(w in words1 for w in half1)
score_after = any(w in words1 for w in half2)
score = score_before or score_after
return (score, score_before, score_after)
df2 = pd.DataFrame([get_scores(s1, s2) for s1, s2 in
zip(df_input['Keyword'], df_input['Returns'])],
dtype=int, columns=['Score', 'Score_before', 'Score_after'])
out = df_input.join(df2)
output:
Keyword Returns Score Score_before Score_after
0 apple banana, orange Fruit; Banana Vendor 1 0 1
1 apple orange ?banana " Blendor :Kaka Orange 1 0 1
2 potato, piercing pot hole piercing Fruit Banana takes a lot 1 1 0
3 armor hard known bullet jacket gun 0 0 0