I'm trying to create the most optimal query where the database would return the names of readers who often borrow sci-fi books. That's what I'm trying to optimize:
SELECT reader.name,
COUNT (CASE WHEN book.status_id = 1 AND book.category_id = 2 THEN 1 END)
FROM reader
JOIN book ON book.reader_id = reader.id
GROUP BY reader.name
ORDER BY COUNT (CASE WHEN book.status_id = 1 AND book.category_id = 2 THEN 1 END) DESC
LIMIT 10;
How can I improve my query other than with INNER JOIN or memory consumption increase?
This is my ERD diagram:
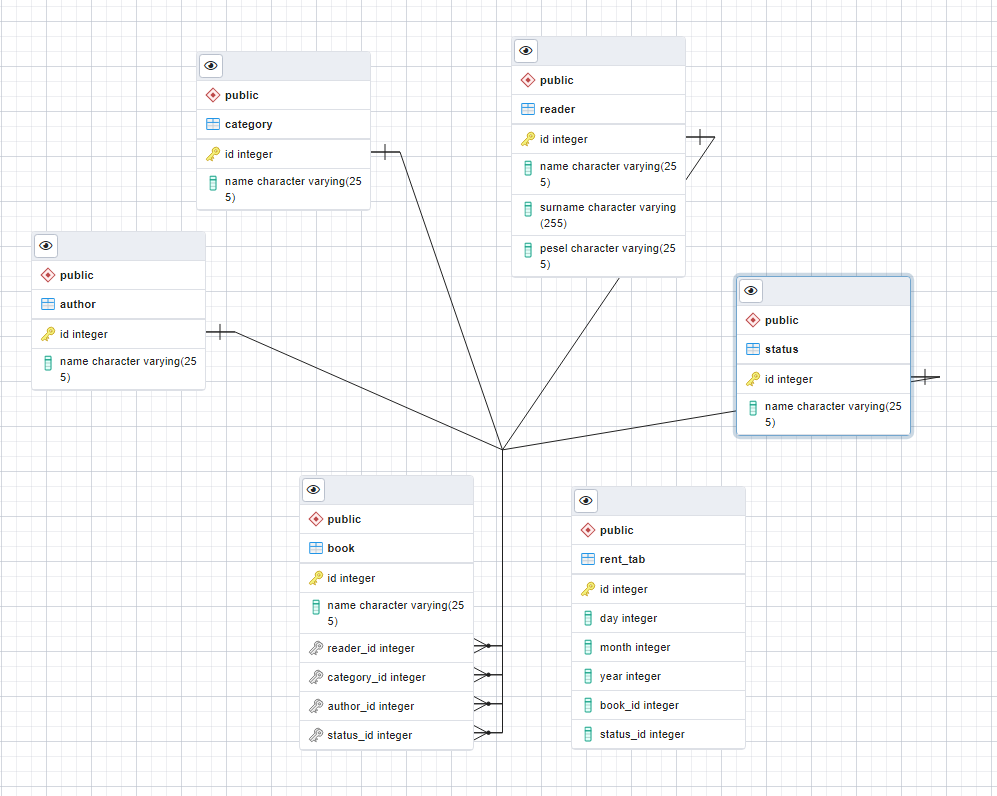
CodePudding user response:
You could try to add your criteria in your join statement and just use the total count. It really depends on how much data you have etc....
SELECT reader.name,
COUNT(1) AS COUNTER
FROM reader
JOIN book ON book.reader_id = reader.id
AND book.status_id = 1
AND book.category = 2
GROUP BY reader.name
ORDER BY COUNTER DESC
LIMIT 10;
CodePudding user response:
Assuming at least 10 readers that pass the criteria (like another answer also silently assumes), else you get fewer than 10 result rows.
Start with the filter. Aggregate & limit before joining to the second table. Much cheaper:
SELECT r.reader_id, r.surname, r.name, b.ct
FROM (
SELECT reader_id, count(*) AS ct
FROM book
WHERE status_id = 1
AND category_id = 2
GROUP BY reader_id
ORDER BY ct DESC, reader_id -- tiebreaker
LIMIT 10
) b
JOIN reader r ON r.id = b.reader_id;
ORDER BY b.ct DESC, r.reader_id -- tiebreaker
A multicolumn index on (status_id, category_id) would help a lot. Or an index on just one of both columns if either predicate is very selective. If performance of this particular query is your paramount objective, have this partial multicolumn index:
CREATE INDEX book_reader_special_idx ON book (reader_id)
WHERE status_id = 1 AND category_id = 2;
Typically, you'd vary the query, then this last index is too specialized.
Additional points:
Group by
reader_id, which is the primary key (I assume) and guaranteed to be unique - as opposed toreader.name! Your original is likely to fail completely,namebeing just the "first name" from the looks of your ERD.
It's also typically substantially faster to group by anintegerinstead ofvarchar(25)(two times). But that's secondary, correctness comes first.Also output
surnameandreader_idto disambiguate identical names. (Even name & surname are not reliably unique.)count(*)is faster thancount(1)while doing the same, exactly.Add a tiebreaker to the
ORDER BYclause to get a stable sort order and deterministic results. (Else, the result can be different every time with ties on the count.)