Suppose I have this df:
df = pd.DataFrame(
{'id': [1, 2, 3, 4, 5],
'actual': [412.6,741.24,1098.30,20025.87,1506.0],
'calculated': [315.24,517.61,998.38,7438.03,1503.32]}
)
df
id actual calculated
0 1 412.60 315.24
1 2 741.24 517.61
2 3 1098.30 998.38
3 4 20025.87 7438.03
4 5 1506.00 1503.32
And I want to plot a histogram of actual and calculated side-by-side for comparison. This code didn't work as intended.
fig, ax = plt.subplots()
a_heights, a_bins = np.histogram(df['actual'])
b_heights, b_bins = np.histogram(df['calculated'], bins=a_bins)
width = (a_bins[1] - a_bins[0])/3
ax.bar(a_bins[:-1], a_heights, width=width, facecolor='cornflowerblue')
ax.bar(b_bins[:-1] width, b_heights, width=width, facecolor='seagreen')
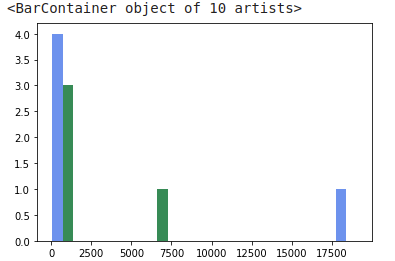
I want to show the lengths on y-axis (412.60/315.24; 741.24/517.61 etc)
CodePudding user response:
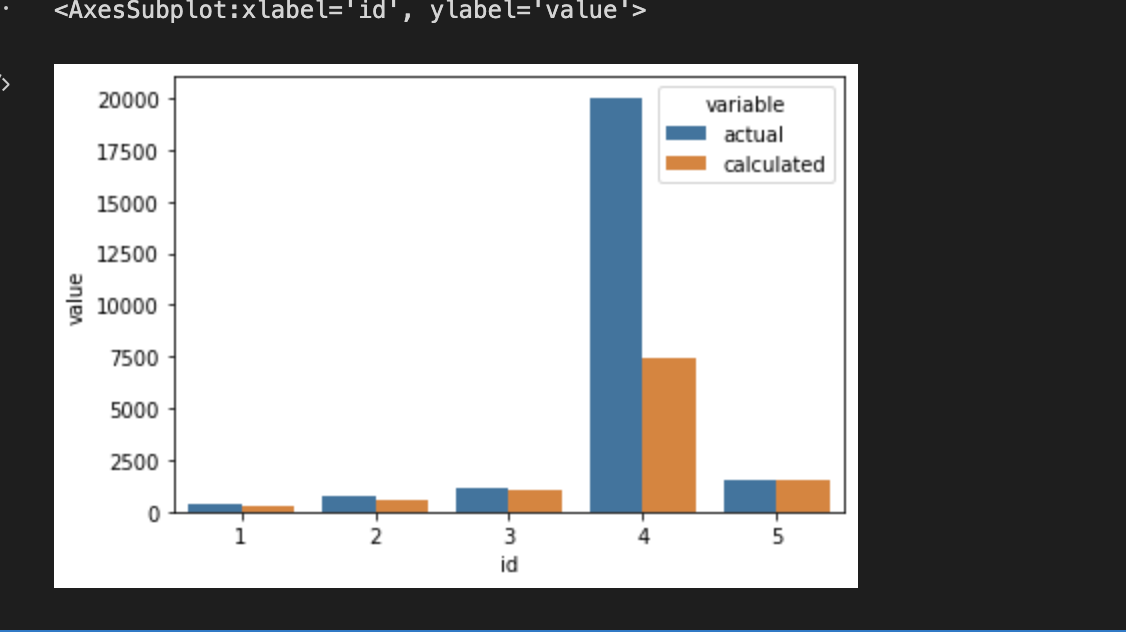
Use seaborn it's easier to manipulate side by side bar plots than matplotlib
import seaborn as sns
df_m = df.melt(id_vars='id')
sns.barplot(x='id', y='value', hue='variable', data=df_m)
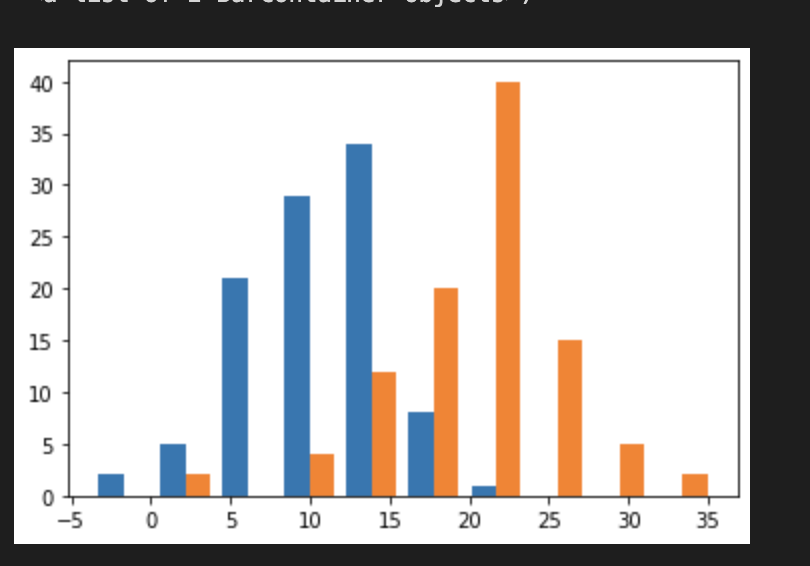
Also for sake of completion giving an example of matplotlib side by side histograms.
import matplotlib.pyplot as plt
x = np.random.normal(10,5,100)
y = np.random.normal(20,5,100)
plt.hist([x, y])